在计算机领域,谈到一致性这个词时,你会想到CAP理论的 consistency,或者数据 ACID 中的 consistency,或者 cache 一致性协议的 coherence,还是 Raft/Paxos 中的 consensus?
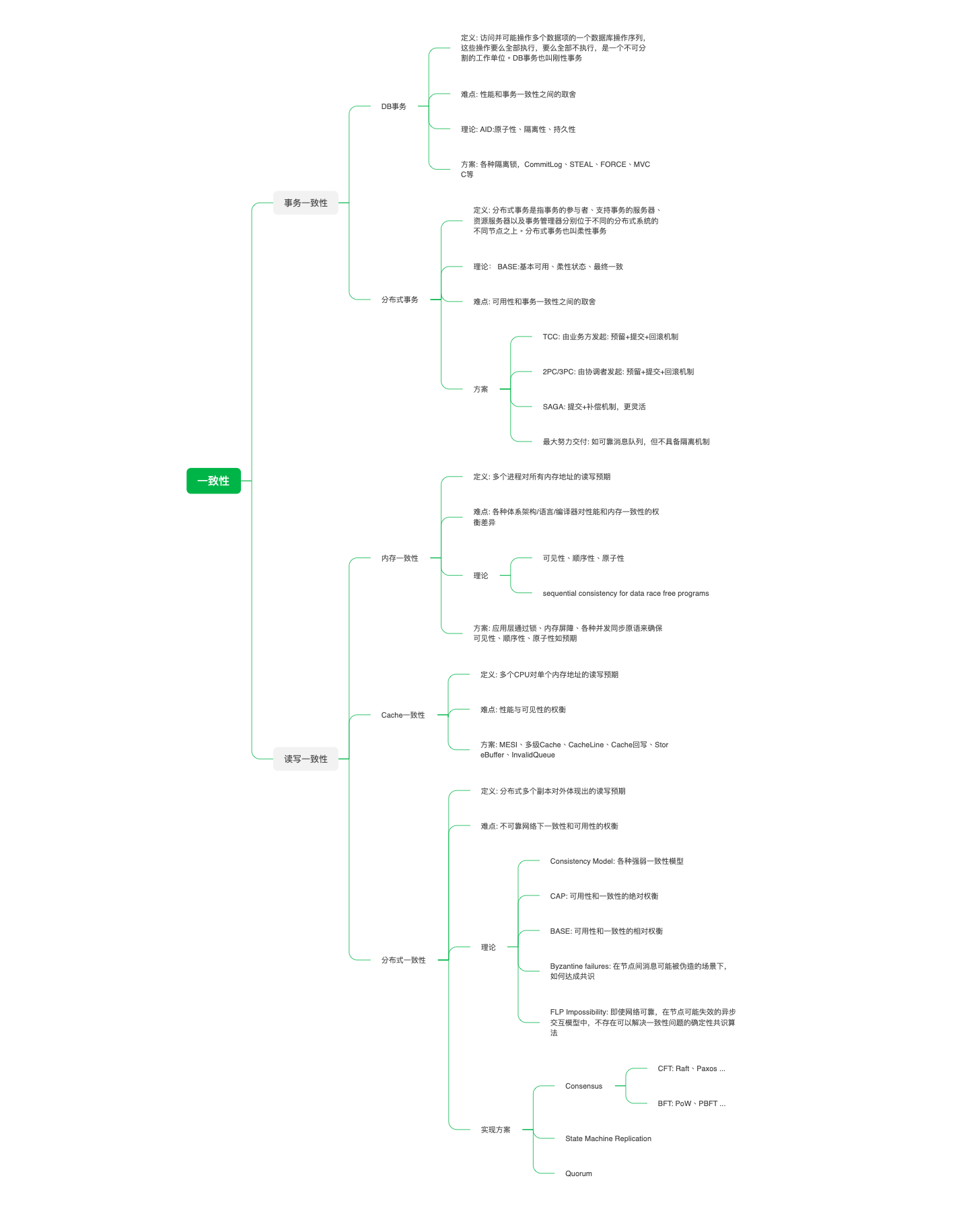
一致性大概是开发者最容易造成困惑的概念之一,在很多中文文献中,都将consistency,coherence,consensus 三个单词统一翻译为”一致性”,但是它们的意义是有所不同的。本文尝试以”一致性”为线头,梳理下相关概念,以及它们之间的区别和联系。
Consensus
更准确的翻译是共识,共识是容错分布式系统中的一个基本问题,共识的本质是多个节点就某个提议达成一致。在分布式系统下,由于节点故障,网络时延,网络分区等问题的存在,2PC/3PC这类强一致事务手段通常是不可取的: 任何节点故障或网络问题都会阻塞整个事务,降低系统的可用性,并且系统节点越多,可用性受影响越大。为了解决这个矛盾,分布式系统通常采用状态机复制+多数投票的机制来构建高可用容错系统:
- 状态机复制(State Machine Replication): 它的理论基础是任何初始状态一样的状态机(如KV Store),如果执行的命令日志(包括新增、修改、删除等任何操作本质都将转化为新的命令日志追加)一样,则它们的状态机最终状态也将一样(KV数据一致)。如此不需要强制这些命令在各个节点是同时开始、同步完成的,只需要将连续的命令日志同步给其他节点(这个步骤也叫日志复制Log Replication),允许在此期间节点存在内部状态的不一致(只要这些不一致不被外观察到),所有的分布式节点的最终状态会达成一致。
- 投票机制(Quorum)): 少数服从多数原则,如果能在多数节点达成一致时就作出不可推翻的最终决策,那么就可以容忍少数节点的不可用,这也就打破了前面说的节点数越多,可用性越低的悖论
在状态机复制的场景下,Paxos/Raft 等共识算法被用来确保各个复制状态机(节点)的日志是一致的,但Paxos/Raft 本身对外不直接体现出一致性(Consistency),一致性是应用层的决策,比如Raft算法中,写操作成功,仅仅意味着超过半数节点对该写日志进行Commit(命令日志一致),但不保证它们对该命令进行了Apply(状态机一致),这一层就是交由应用层去灵活实现的,类似的应用层取舍点还包括Follower是否提供读服务,网络分区后Follower/Candidate是否对外提供读服务等等,因此不同的应用可以基于Raft算法实现不同的一致性,比如ETCD基于Raft支持线性一致性(后面会聊到这个概念)的读写操作。从另一个角度来说,共识算法可以理解为达成一致的一种算法手段。
Paxos/Raft属于宕机容错(CFT,Crash Fault Tolerance)算法,因为它们只容忍了节点/网络故障,没有考虑节点不可信任,可能”作恶”的问题,如经典的拜占庭将军问题。能够(一定程度)容忍拜占庭问题的共识算法被称为拜占庭容错(Byzantine Fault Tolerance)算法,典型如POW(Proof of Work)、POS(Proof of Stake)、PBFT(Practical Byzantine Fault Tolerance)算法等,BFT算法通常比CFT算法实现成本更高,它通常适合用在公网,去中心化的情形下,如区块链场景。
ACID Consistency
ACID 中的C指代Consistency or Correctness(From WIKI)),但通常被译作事务的一致性,主流理解这里的一致性是指数据库的一致性约束,包括唯一键、外键约束,级联,触发器等。在事务开始之前和事务结束以后,都必须遵守这些不变量,保证数据库的一致性状态不被破坏。即ACID是数据为支持事务提供的四种正交的机制支撑。
不过也有对ACID的另一种理解,将C纳入到通用的一致性模型(这篇文章总结的一致性模型也不错,将事务一致性和分布式一致性整合到了一起),从这个角度而言,ACID中的AID只是数据库提供的实现事务的手段,C是应用层使用事务的目的。前面说的数据库级联、触发器等相关约束,只是数据库系统为应用层提供的可选辅助机制。这种理解的本质是将DB数据一致性的概念和职责从数据库层提到了应用层,将事务一致性的概念拓宽了(从数据库的约束一致到应用层的状态一致)。应用层通过使用事务来获得数据一致性(广义的事务数据一致性),而不是数据库通过一致性(狭义的数据库一致性约束,受限于具体数据库系统)去实现事务。我个人比较认可这种理解,因为事务虽然起源于数据库,而如今在其他各种分布式系统也推广开来,这种理解有助于在数据库事务(刚性事务)和后面提到的分布式事务(柔性事务)联系起来,相互借鉴学习。
事务一致性后面提到的分布式一致性是有所不同的,分布式一致性讨论的粒度是单个读写操作,这些读写操作对外表现的读写预期如何。事务一致性讨论的粒度是单个事务,而单个事务包含多个读写操作,因此事务一致性还需要考虑原子性(单个事务会不会只生效了一半)和隔离性(不同事务会不会交织影响)。
CAP Consistency
CAP 理论中的 C 也就是我们常说的分布式系统中的一致性,更确切地说,指的是分布式一致性中的一种: 线性一致性(Linearizability)。
谈到 CAP,网上各种理解也有很多版本,我个人更推荐的CAP资料来自于cap faq。简单总结,在一个分布式的存储系统(即副本集)中,只能Consistency, Availability, Partition三选二,而由于在大规模的分布式系统中,网络不可靠几乎是不可避免的,即Partition网络分区容忍是必选项,因此对系统设计需要在AP(出现分区时可能响应过期的数据,即舍弃一致性)和CP(出现分区时阻塞请求直到故障恢复,在此期间整个系统不可用)之间权衡。
很多时候我们会用 CAP 模型去评估一个分布式系统,但这篇文章提到了 CAP 理论的局限性,因为 CAP 理论是一个被过度简化的理论模型,按照 CAP 理论,很多系统包括 MongoDB,ZooKeeper 既不满足一致性(线性一致性),也不满足可用性(任意一个工作中的节点都要可以处理请求),但这并不意味着它们不是优秀的系统,而是 CAP 定理本身并没有考虑强弱一致性、处理时延、硬件故障、部分可用、SLA等等。这里不再展开,推荐阅读原文。
正因为 CAP 中对C和A的定义过度理想化,后来又有人提出了BASE 理论,即基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency)。BASE的核心思想是即使无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方法来使系统达到最终一致性(关于一致性和可用性的取舍,这篇亚马逊CTO Werner Vogels的博客值得一读)。显然,最终一致性弱于 CAP 中的 线性一致性。很多分布式系统都是基于 BASE 中的”基本可用”和”最终一致性”来实现的,比如 MySQL/PostgreSQL Replication 异步复制等。
前面说到,CAP 中的 C 是分布式系统的一致性模型中的一种,这里的分布式一致性,更确切地说,应该是分布式多副本场景下,系统对用户/客户端保证的读写一致性约定。大部分时候我们说的分布式系统一致性模型,都是针对这种情形(我个人将其理解为读写一致性,对应的,还有事务一致性,文末会做个小结),以下再展开说明下。
在分布式共享内存系统或者分布式数据存储中,数据一致性模型指定程序员和系统之间的契约,系统保证如果程序员遵守规则,则存储器将是一致的,并且读取,写入或更新存储器的结果将是可预测的。我们最常用于讨论的便是复制状态机(Replicated state machines)的一致性问题,比如 etcd, zookeeper,当进程 A 执行 set x 3 时,进程 B 是否能在 A 执行完成后立即读到 x 的新值。这个问题在单节点上是显而易见的,但在分布式中,对进程 来说,则需要通过一致性模型来确保server 给出的结果可预测。分布式系统中的一致性有强弱之分,理想情况下,当进程写入 replicate 中的某个节点,其改变会被立即同步到集群其它节点,其它进程 能立即读取到该值。弱一些的一致性是最终一致性,即操作完成之后的某段时间内可能各个节点的数据副本不一致(导致不同进程 访问到的数据会不一致),但最终会是一致的。比如 DNS 服务。
要理解分布式一致性,先来谈谈分布式中几个必要的概念: 时间,事件,和顺序。
分布式系统的时间主要分为物理时间和逻辑时间两种,物理时间是指程序能够直接获取到的 OS 时间,在分布式系统中,由于光速有限,你永远无法同步两台计算机的时间。想要在分布式中仅依靠物理时间来决定事件的客观先后顺序是不可能的。因此分布式系统中,通常使用逻辑时间来处理事件的先后关系。
分布式中的事件不是瞬间的概念,它有一个起始和结束时间,因此不同进程 发起的事件可能发生重叠,对于发生重叠的事件,我们说它们是并发执行的,在物理时间上是不分先后的。
理想情况下,我们希望整个分布式系统中的所有事件都有先后顺序,这种顺序就是全序,即整个事件集合中任意两个事件都有先后顺序。但 1.物理时间是很难同步的,2. 网络是异步的,因此在分布式系统中,想要维持全序是非常困难的。不同的节点对两个事件谁先发生可能具有不同的看法,并且大部分时候我只需要知道偏序关系,用于确保因果关系。所谓偏序关系是指:
- 如果a和b是同一个进程中的事件,并且a在b前面发生,那么 a->b
- 如果a代表了某个进程的消息发送事件,b代表另一进程中针对这同一个消息的接收事件,那么a->b
- 如果 a->b且b->c,那么a->c (传递性)
逻辑时间中的 Lamport Clock和Vector Clock等都可以用于建立偏序关系。
顺序一致性(Sequential Consistency)
Leslie Lamport 在1979年提出了Sequential Consistency, Leslie Lamport的定义如下:
A multiprocessor is said to be sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.[How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs by Leslie Lamport ,1979]
这个定义比较晦涩,通常来讲,他可以分为两个部分:
- 单个节点的事件历史在全局历史上看符合程序顺序
- 事件历史在各个节点上看全局一致
约束1保证了单个节点的所有事件是按照程序中指定的顺序执行的,约束2保证了所有的事件是原子的,不会相互干扰。更通俗的理解是,将整个分布式系统想象成一个调度器,将多个进程 的请求看做是多个FIFO请求队列, 调度器依次处理队列中的请求,并在多个队列中不断切换。是的,这和Go调度器原理类似,只不过我们探讨一致性模型时,会将系统规约为一个黑盒,从进程的角度来看这个黑盒对外表现出的一致性强弱。
下面举个例子来加深理解,假设我们有个分布式 KV 系统,以下是四个进程 对其的操作顺序和结果:
1 | A: --W(x,1)-- |
其中W(x,1)表示更新 x 的值为1,R(x,1)表示读出 x 的值为2,横向为物理时间,事件两边的’-‘代表事件持续时间,那么按照我们前面对顺序一致性的描述,显然这个 KV 系统是满足顺序一致性的。
如果我们将进程 C 和 D 的 R(x,1) 和 R(x,2) 对换一下,也就是如果 C 和 D 都是先读出 x 为 2,再读出 x 为 1,那么还满足顺序一致性么,答案是肯定的,因为仍然能够找出一个全局的执行顺序: B W(x,2) -> A W(x,1) -> C R(x,2) -> D R(x,2) -> C R(x,1) -> D R(x,1),这个顺序满足前面提到的两点约束,即使直观上看来,这是”错误的一致性”。
如果我们只是把进程 D 的两个 R 操作对换,那么我们说这个系统是不满足顺序一致性的,因为你无法找出一个全局顺序满足以上两点约束。同样,如果 W(x,1) 和 W(x,2) 都发生在进程 A 中,那么系统也不满足顺序一致性。
线性一致性(Linearizability)
也叫做strong consistency或者atomic consistency,于 1987年提出,线性一致性强于顺序一致性,是程序能实现的最高的一致性模型,也是分布式系统用户最期望的一致性。 与顺序一致性相比,线性一致性只多了一条约束:如果事件A开始时间晚于事件B结束时间,则在最终事件历史中,要求B在A前。或者换句话说:事件生效时间是在事件开始时间到结束事件之间的某个时刻。 举个例子:
1 | A: --W(x,1)-- |
这个案例是满足线性一致性的,因为W(x,1)和W(x,2)两个事件是同时发生的,因此事件生效点可能出现在开始和结束之间的任意点,就这个例子来讲,全局事件历史为: B-W(x, 2), C-R(x,2), A-W(x,1), D-R(x,1), C-R(x,1),其中D-R(x,1), C-R(x,1)可以对换。
如果将 D 的 R(x,1)改为 R(x,2),则不满足线性一致性,因为 C 的 R(x,1) 和 D 的 R(x,2)都发生在 A, B 的 W 事件之后,因此它们应该对 x 的值结果具有相同的视角,不会读出不一致的结果。
如果说顺序一致性只保证单节点事件先后顺序的话,线性一致性还保证节点间的事件先后顺序,因此线性一致性的实现是非常困难的,一方面它需要一个全局同步的时钟(顺序一致性不需要全局同步的时钟),另一方面,越严格的一致性,会让分布式系统的复杂度更高,并且与之对应的,性能也会更差。
除了线性一致性和顺序一致性外,还一些其它更弱的一致性模型,比如因果一致性,最终一致性等,这里不再赘述。理解一致性本身和一些基础概念之后,理解其它一致性都不难。
Cache Coherence & Meomory Consistency
Cache Coherence 被译为缓存一致性、缓存连贯性或缓存同调。我在Cache一致性和内存一致性中详细聊了Cache Coherence 和 Memory Consistency,其中提到: Cache Conherence本质是多个CPU对同一内存地址的读写预期,这通常通过缓存一致性协议(如MESI)来保证,如果多CPU对同一内存地址的读写满足顺序一致性,那么我们就说该多CPU架构是缓存一致的。
既然Cache Coherence的目标是顺序一致性,那么常见架构体系的 Memory Consistency 满足顺序一致性么,来看个例子:
初始状态下,x = 0, y = 0
| 进程 A | 进程 B |
|---|---|
| x=1 | y=1 |
| r1=y | r2=x |
按照顺序一致性的定义,我们将四条指令交叉任意排列,最终可能得到三种结果: r1==1,r2==0,r1==0,r2=1, r1=1,r2=1 三种结果,但不可能得到 r1=0,r2=0 的结果,因为这意味着全局执行顺序为 r1=y, r2=x, x=1, y=1,并不符合单个进程内部的执行顺序。那么实际上,这段程序会输出r1=0,r2=0的结果么?答案是会的,原因如下:
- 编译器指令重排,编译器会在不影响程序语义的情况下,调整代码中的指令顺序。但编译器只能够解析显示语义,即单线程上下文,它无法(或者说非常难)解析程序的隐式语义,即程序的多线程上下文依赖。
- CPU指令乱序执行,由于内存读取非常慢,CPU在不影响单线程语义的情况下,会将数据提前加载到缓存,提高执行效率。这就可能造成CPU指令处理顺序和程序指令顺序不一致,由于CPU 乱序只保证单线程语义,因此同样无法解析程序逻辑隐私因果关系,也可能造成结果不符程序预期。
- 缓存一致性,由于 LB/SB 的存在,缓存一致性是有极短延迟的,可能某个共享数据被CPU更新并写入到 SB(Store Buffer)中,其它 CPU 并不能即时看到。
基于以上三点,现代 CPU 架构基本都是不支持顺序一致性的,因为其需要非常高昂的代价,严重限制编译器和硬件的优化能力。比如顺序一致性要求处理器按照程序序(program order)来执行程序,但在大部分情况下,这是没必要的。因此,现代硬件体系遵循的其实是: sequential consistency for data race free programs,即对没有 data race 的程序来说,是满足顺序一致性的(编译器能够分析上下文相关性),但如果涉及到 data race,程序员需要使用 compile barrier 和 memory barrier 来限制编译器和 CPU 的乱序能力,以确保多线程程序执行结果如预期。
另外,系统架构、编译器、编程语言通常会提供默认的不同强弱的内存一致性(也叫做内存模型,如Go Memory Model),以及相关并发同步机制。
小结
按照个人理解,对以上提到的各种一致性做个小结: