一. Go GC 要点
先来回顾一下GC的几个重要的阶段:
Mark Prepare - STW
做标记阶段的准备工作,需要停止所有正在运行的goroutine(即STW),标记根对象,启用内存屏障,内存屏障有点像内存读写钩子,它用于在后续并发标记的过程中,维护三色标记的完备性(三色不变性),这个过程通常很快,大概在10-30微秒。
Marking - Concurrent
标记阶段会将大概25%(gcBackgroundUtilization)的P用于标记对象,逐个扫描所有G的堆栈,执行三色标记,在这个过程中,所有新分配的对象都是黑色,被扫描的G会被暂停,扫描完成后恢复,这部分工作叫后台标记(gcBgMarkWorker)。这会降低系统大概25%的吞吐量,比如MAXPROCS=6,那么GC P期望使用率为6*0.25=1.5,这150%P会通过专职(Dedicated)/兼职(Fractional)/懒散(Idle)三种工作模式的Worker共同来完成。
这还没完,为了保证在Marking过程中,其它G分配堆内存太快,导致Mark跟不上Allocate的速度,还需要其它G配合做一部分标记的工作,这部分工作叫辅助标记(mutator assists)。在Marking期间,每次G分配内存都会更新它的”负债指数”(gcAssistBytes),分配得越快,gcAssistBytes越大,这个指数乘以全局的”负载汇率”(assistWorkPerByte),就得到这个G需要帮忙Marking的内存大小(这个计算过程叫revise),也就是它在本次分配的mutator assists工作量(gcAssistAlloc)。
Mark Termination - STW
标记阶段的最后工作是Mark Termination,关闭内存屏障,停止后台标记以及辅助标记,做一些清理工作,整个过程也需要STW,大概需要60-90微秒。在此之后,所有的P都能继续为应用程序G服务了。
Sweeping - Concurrent
在标记工作完成之后,剩下的就是清理过程了,清理过程的本质是将没有被使用的内存块整理回收给上一个内存管理层级(mcache -> mcentral -> mheap -> OS),清理回收的开销被平摊到应用程序的每次内存分配操作中,直到所有内存都Sweeping完成。当然每个层级不会全部将待清理内存都归还给上一级,避免下次分配再申请的开销,比如Go1.12对mheap归还OS内存做了优化,使用NADV_FREE延迟归还内存。
STW
在Go调度模型中我们已经提到,Go没有真正的实时抢占机制,而是一套协作式抢占(cooperative preemption),即给G(groutine)打个标记,等待G在调用函数时检查这个标记,以此作为一个安全的抢占点(GC safe-point)。但如果其它P上的G都停了,某个G还在执行如下代码:
1 | func add(numbers []int) int { |
add函数的运行时间取决于切片的长度,并且在函数内部是没有调用其它函数的,也就是没有抢占点。就会导致整个运行时都在等待这个G调用函数(以实现抢占,开始处理GC),其它P也被挂起。这就是Go GC最大的诟病: GC STW时间会受到G调用函数的时机的影响并被延长,甚至如果某个G在执行无法抢占的死循环(即循环内部没有发生函数调用的死循环),那么整个Go的runtime都会挂起,CPU 100%,节点无法响应任何消息,连正常停服都做不到。pprof这类调试工具也用不了,只能通过gdb,delve等外部调试工具来找到死循环的goroutine正在执行的堆栈。如此后果比没有被defer的panic更严重,因为那个时候的节点内部状态是无法预期的。
因此有Gopher开始倡议Go使用非协作式抢占(non-cooperative preemption),通过堆栈和寄存器来保存抢占上下文,避免对抢占不友好的函数导致GC STW延长(毕竟第三方库代码的质量也是参差不齐的)。相关的Issue在这里。好消息是,Go1.14(目前还是Beta1版本,还未正式发布)已经支持异步抢占,也就是说:
1 | // 简单起见,没用channel协同 |
这段代码在Go1.14中终于能输出OK了。这个提了近五年的Issue: runtime: tight loops should be preemptible #10958前几天终于关闭了。不得不说,这是Go Runtime的一大进步,它不止避免了单个goroutine死循环导致整个runtime卡死的问题,更重要的是,它为STW提供了最坏预期,避免了GC STW造成了性能抖动隐患。
二. Go GC 度量
1. go tool prof
Go 基础性能分析工具,pprof的用法和启动方式参考go pprof性能分析,其中的heap即为内存分配分析,go tool默认是查看正在使用的内存(inuse_heap),如果要看其它数据,使用go tool pprof --alloc_space|inuse_objects|alloc_objects。
需要注意的是,go pprof本质是数据采样分析,其中的值并不是精确值,适用于性能热点优化,而非真实数据统计。
2. go tool trace
go tool trace可以将GC统计信息以可视化的方式展现出来。要使用go tool trace,可以通过以下方式生成采样数据:
- API:
trace.Start - go test:
go test -trace=trace.out pkg - net/http/pprof:
curl http://127.0.0.1:6060/debug/pprof/trace?seconds=20
得到采样数据后,之后即可以通过 go tool trace trace.out 启动一个HTTP Server,在浏览器中查看可视化trace数据:
里面提供了各种trace和prof的可视化入口,点击第一个View trace可以看到追踪总览:
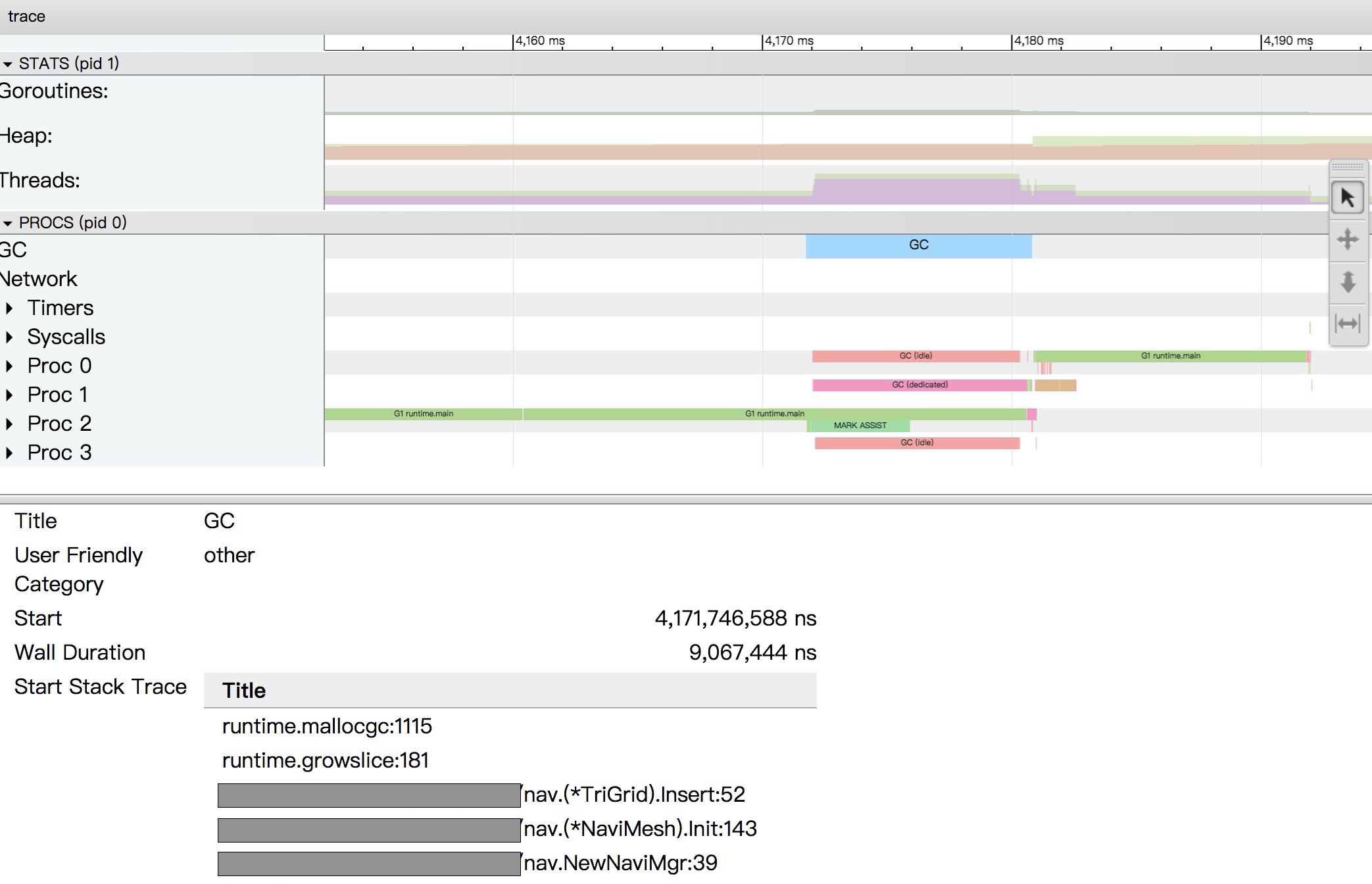
包含的信息量比较广,横轴为时间线,各行为各种维度的度量,通过A/D左右移动,W/S放大放小。以下是各行的意义:
- Goroutines: 包含GCWaiting,Runnable,Running三种状态的Goroutine数量统计
- Heap: 包含当前堆使用量(Allocated)和下次GC阈值(NextGC)统计
- Threads: 包含正在运行和正在执行系统调用的Threads数量
- GC: 哪个时间段在执行GC
- ProcN: 各个P上面的goroutine调度情况
除了View trace之外,trace目录的第二个Goroutine analysis也比较有用,它能够直观统计Goroutine的数量和执行状态:
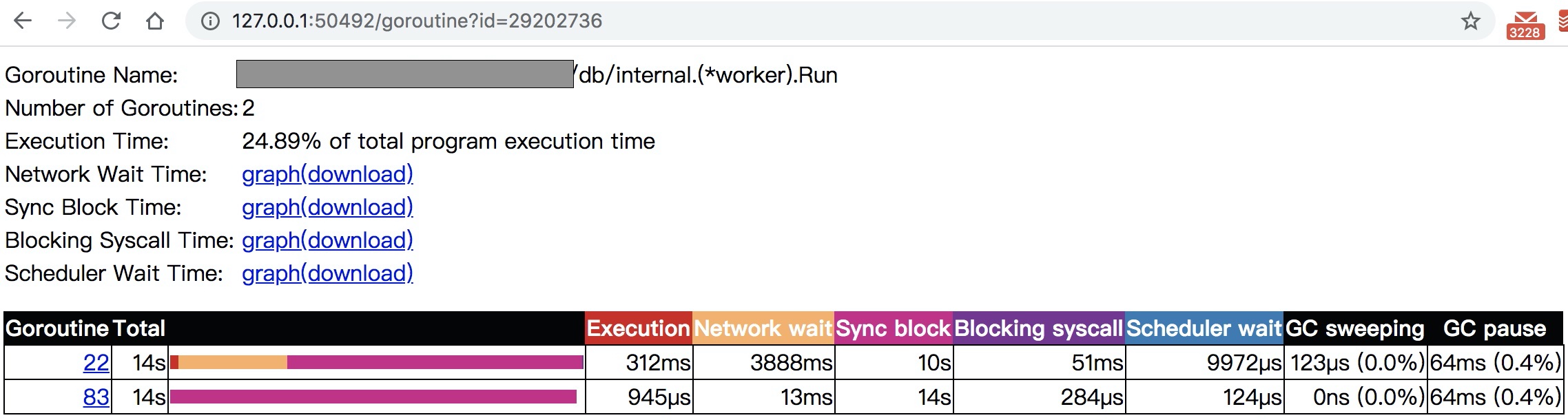
通过它可以对各个goroutine进行健康诊断,各种network,syscall的采样数据下载下来之后可以直接通过go tool pprof分析,因此,实际上pprof和trace两套工具是相辅相成的。
3. GC Trace
GC Trace是Golang提供的非侵入式查看GC信息的方案,用法很简单,设置GCDEBUG=gctrace=1环境变量即可:
1 | GODEBUG=gctrace=1 bin/game |
下面是各项指标的解释:
1 | gc 1 @0.039s 3%: 0.027+4.5+0.015 ms clock, 0.11+2.3/4.0/5.5+0.063 ms cpu, 4->4->2 MB, 5 MB goal, 4 P |
4. MemStats
runtime.MemStats记录了内存分配的一些统计信息,通过runtime.ReadMemStats(&ms)获取,它是runtime.mstats的对外版(再次可见Go单一访问控制的弊端),MemStats字段比较多,其中比较重要的有:
1 | // HeapSys |
程序可以通过定期调用runtime.ReadMemStatsAPI来获取内存分配信息发往时序数据库进行监控。另外,该API是会STW的,但是很短,Google内部也在用,用他们的话说:”STW不可怕,长时间STW才可怕”,该API通常一分钟调用一次即可。
5. ReadGCStats
debug.ReadGCStats用于获取最近的GC统计信息,主要是GC造成的延迟信息:
1 | // GCStats collect information about recent garbage collections. |
和ReadMemStats一样,ReadGCStats也可以定时收集,发送给时序数据库做监控统计。
三. Go GC 调优
Go GC相关的参数少得可怜,一如既往地精简:
1. debug.SetGCPercent
一个百分比数值,决定即本次GC后,下次触发GC的阈值,比如本次GC Sweeping完成后的内存占用为200M,GC Percentage为100(默认值),那么下次触发GC的内存阈值就是400M。这个值通常不建议修改,因为优化GC开销的方法通常是避免不必要的分配或者内存复用,而非通过调整GC Percent延迟GC触发时机(Go GC本身也会根据当前分配速率来决定是否需要提前开启新一轮GC)。另外,debug.SetGCPercent传入<0的值将关闭GC。
2. runtime.GC
强制执行一次GC,如果当前正在执行GC,则帮助当前GC执行完成后,再执行一轮完整的GC。该函数阻塞直到GC完成。
3. debug.FreeOSMemory
强制执行一次GC,并且尽可能多地将不再使用的内存归还给OS。
严格意义上说,以上几个API预期说调优,不如说是补救,它们都只是把Go GC本身就会做的事情提前或者延后了,通常是治标不治本的方法。真正的GC调优主要还是在应用层面。我在这篇文章聊了一些Go应用层面的内存优化。
以上主要从偏应用的角度介绍了Golang GC的几个重要阶段,STW,GC度量/调试,以及相关API等。这些理论和方法能在在必要的时候派上用场,帮助更深入地了解应用程序并定位问题。
推荐文献: