CGroup V1
1. CGroup 概念
- Task: 任务,也就是进程,但这里的进程和我们通常意义上的 OS 进程有些区别,在后面会提到。
- CGroup: 控制组,一个 CGroup 就是一组按照某种标准划分的Tasks。这里的标准就是 Subsystem 配置。换句话说,同一个CGroup 的 Tasks 在一个或多个 Subsystem 上使用同样的配置。
- Hierarchy: 树形结构的 CGroup 层级,每个子 CGroup 节点会继承父 CGroup 节点的子系统配置,每个 Hierarchy 在初始化时会有默认的 CGroup(Root CGroup)。
- Subsystem: 子系统,具体的物理资源配置,比如 CPU 使用率,内存占用,磁盘 IO 速率等。一个 Subsystem 只能附加在一个 Hierarchy 上,一个 Hierarchy 可以附加多个 Subsystem。
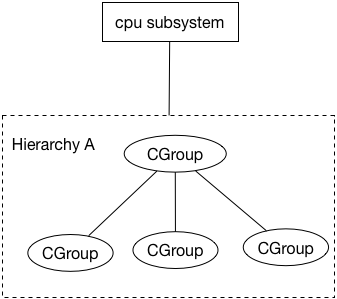
2. CGroup 文件系统
在具体实现中,CGroup 通过虚拟文件系统实现,一个 CGroup 就是一个文件夹,Hierarchy 层级结构通过文件夹结构实现,而每个 CGroup 的 Subsystem 配置和 Tasks 则通过文件来配置。在 Ubuntu 下,可通过lssubsys -m(需要安装cgroup-tools包),查看已有的 Subsystem:
root# lssubsys -m
cpuset /sys/fs/cgroup/cpuset
cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
blkio /sys/fs/cgroup/blkio
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
pids /sys/fs/cgroup/pids
这些是 Ubuntu16.04 上已实现的 Subsystem 和对应 Hierarchy。各个Subsystem 的作用可参考 RedHat CGroup Doc。在其它系统,你可以需要手动挂载虚拟文件系统并建立 Subsystem 和 Hierarchy 的关系:
root# mount -t tmpfs cgroup_root /sys/fs/cgroup
root# mkdir /sys/fs/cgroup/cpu
root# mount -t cgroup cpu -ocpu /sys/fs/cgroup/cpu
/sys/fs/cgroup/cpu 即成为附加(attach)了 CPU Subsystem 的 Hierarchy 的根目录,即 Root CGroup,我们可以在该 CGroup 下创建一个 Child CGroup:
root# mkdir /sys/fs/cgroup/cpu/demo
root# ls /sys/fs/cgroup/cpu/demo
cgroup.clone_children cgroup.procs cpuacct.stat cpuacct.usage cpuacct.usage_percpu cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release tasks
在创建 CGroup 时,就已经生成了一堆文件,一个 CGroup 目录中的内容大概可以分为四类:
- Subsystem Conf: 如附加了 CPU Subsystem 的 CGroup 目录下的 cpu* 文件均为 CPU Subsystem 配置
- Tasks: 在该 CGroup 下的 Tasks,分为两个文件,tasks 和 cgroup.procs,两者记录的都是在该进程 PID 列表,但是有所区别。
- CGroup Conf: CGroup 的一些通用配置,比如 notify_on_release 用于在 CGroup 结构变更时执行 release_agent 中的命令,cgroup.clone_children 用于在 Child CGroup 创建时,自动继承父 Child CGroup 的配置,目前只有 cpuset SubSystem 支持
- Child CGroups: 除以上三种文件外的子目录,如Ubuntu16.04中,每个 Root CGroup 下都有个 docker 目录,它由 Docker 创建,用于管理Docker容器的资源配置
关于 tasks 和 cgroup.procs,网上很多文章将 cgroup 的 Task 简单解释为 OS 进程,这其实不够准确,更精确地说,cgroup.procs 文件中的 PID 列表才是我们通常意义上的进程列表,而 tasks 文件中包含的 PID 实际上可以是 Linux 轻量级进程(LWP) 的 PID,而由于 Linux pthread 库的线程实际上轻量级进程实现的(Linux 内核不支持真正的线程,可通过getconf GNU_LIBPTHREAD_VERSION查看使用的 pthread 线程库版本,Ubuntu16.04上是NPTL2.23(Native Posix Thread Lib),简单来说,Linux 进程主线程 PID = 进程 PID,而其它线程的 PID (LWP PID)则是独立分配的,可通过syscall(SYS_gettid)得到。LWP 在 ps 命令中默认是被隐藏的,在/proc/目录下可以看到。为了区分方便,我们将以 Proc 来表示传统意义上的进程,以 Thread 表示 LWP 进程。
我们可以通过 ps 命令的 -T 参数将 LWP 在 SPID 列显示出来:
root# ps -ef | wc -l
218
root# ps -efT | wc -l
816
root# ps -p 28051 -lfT
F S UID PID SPID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
0 Z root 28051 28051 26889 0 80 0 - 0 exit 10:30 pts/10 00:00:00 [a.out] <defunct>
1 R root 28051 28054 26889 99 80 0 - 12409 - 10:30 pts/10 00:00:10 [a.out] <defunct>
1 R root 28051 28055 26889 99 80 0 - 12409 - 10:30 pts/10 00:00:10 [a.out] <defunct>
以上示例中,Proc 28051 下有两个 Thread (28054,28055),即开了两个子线程。总的来说,Linux 下这种通过 LWP 来实现线程的方式,在一些时候会给用户一些困惑,比如如果我 kill -9 28055(默认在 ps 下看不到),按照 POSIX 标准,28055 “线程”所在的进程会被 Kill掉,因此28051,28054,28055三个进程都会被杀掉,感觉就很诡异。感兴趣的可以看看这篇文章)。
当要向某个 CGroup 加入 Thread 时,将Thread PID 写入 tasks 或 cgroup.procs 即可,cgroup.procs 会自动变更为该 Task 所属的 Proc PID。如果要加入 Proc 时,则只能写入到 cgroup.procs 文件(未解),tasks 文件会自动更新为该 Proc 下所有的 Thread PID。可以通过cat /proc/PID/cgroup查看某个 Proc/Thread 的 CGroup 信息,
3. 一个实例
1 |
|
这段代码简单创建了四个死循环线程,运行:
1 | root# gcc -pthread t.c && ./a.out |
通过 htop/top(top 默认不会显示 LWP) 看到现在四个 CPU 会被吃满,为了限制资源,我们创建一个 CGroup:
1 | root# mkdir /sys/fs/cgroup/cpu/wdj |
最终我们通过 htop 得到的效果如下:
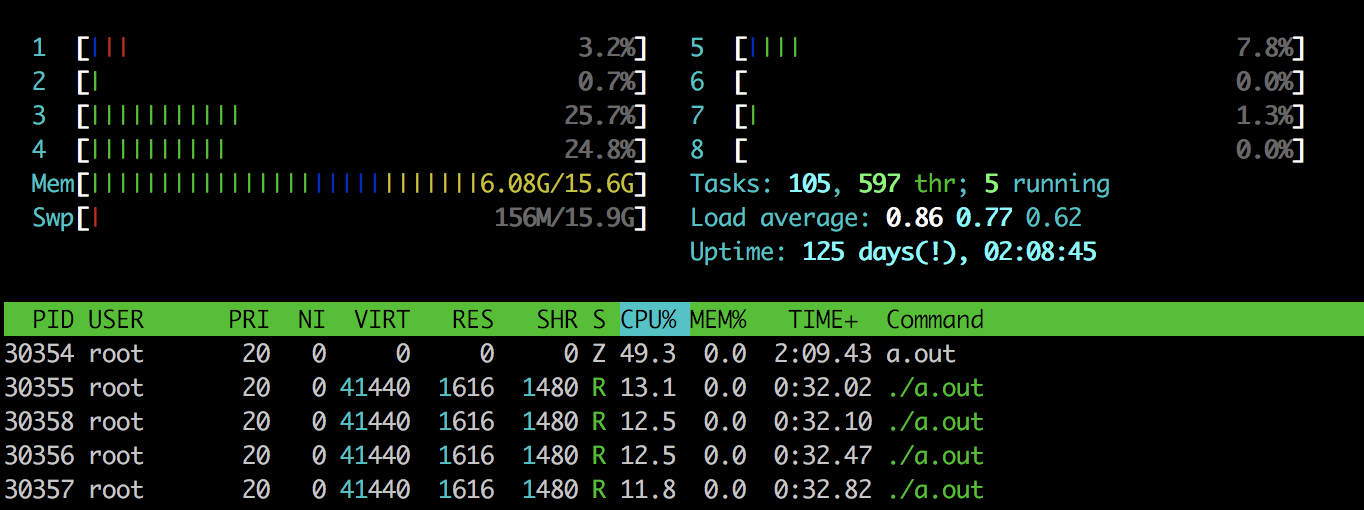
如果我们只将 Thread PID 如30356写入 /sys/fs/cgroup/cpu/wdj/tasks,则只会限制thread#1的CPU使用率。总结一下:
- 将 Thread PID 写入 tasks: 仅对该”线程”(LWP) 生效
- 将 Thread PID 写入 cgroup.procs: 会加入整个 Proc PID
- 将 Proc PID 写入 tasks: 没有效果,写不进去
- 将 Proc PID 写入 cgroup.procs: 会加入整个 Proc PID
表现有点怪异,还没找到具体原因,总的来说,目前的 CGroup 还有点乱:
- Subsystem, Hierarchy, CGroup 三者的结构有点乱,将对进程的分组和对资源的控制混在了一起
- 由于 Linux 通过 LWP 实现 Thread,导致 CGroup 看起来可以对线程实现控制,但这方面机制不够健全,比如前面提到的加入机制
CGroup V2
CGroup V2 在 Linux Kernel 4.5中被引入,并且考虑到其它已有程序的依赖,V2 会和 V1 并存几年。针对于 CGroup V1 中 Subsystem, Herarchy, CGroup 的关系混乱,CGroup V2 中,引入 unified hierarchy 的概念,即只有一个 Hierarchy,仍然通过 mount 来挂载 CGroup V2:
mount -t cgroup2 none $MOUNT_POINT
挂载完成之后,目录下会有三个 CGroup 核心文件:
- cgroup.controllers: 该文件列出当前 CGroup 支持的所有 Controller,如: cpu io memory
- cgroup.procs: 在刚挂载时,Root CGroup 目录下的 cgroup.procs 文件中会包含系统当前所有的Proc PID(除了僵尸进程)。同样,可以通过将 Proc PID 写入 cgroup.procs 来将 Proc 加入到 CGroup
- cgroup.subtree_control: 用于控制该 CGroup 下 Controller 开关,只有列在 cgroup.controllers 中的 Controller 才可以被开启,默认情况下所有的 Controller 都是关闭的。
这三个文件在所有的 CGroup 中都会生成,除此之外,在非 Root CGroup 下,还会有一个 cgroup.events 文件,该文件的 populated 字段会指出当前 CGroup 下的所有存活的 Proc PID,为1则表示其下存活的 Proc PID 数量>1,否则populated为0。这用于 CGroup V1的 release_agent 等事件通知,因为当最后一个进程退出 CGroup 时,cgroup.events 文件会被修改,从而触发事件。
# 查看当前 CGroup 支持的所有 Controllers
root# cat cgroup.controllers
cpu io memory
# 开启和关闭 Controller
root# echo "+cpu +memory -io" > cgroup.subtree_control
在 CGroup V2 中,A CGroup 开启了某个 Controller,则其直接子 CGroup B会生成对应的 Controller 接口文件(如 cpu.cfs_quota_us),并且B CGroup 的 cgroup.controllers 会更新。B也可以选择开启或关闭该 Controller,但影响的是 B 的直接子 CGroup。并且只有没有 Tasks 的 CGroup 即中间节点可以开关 Controller,只有叶子节点(和根节点)可以执行资源配置。这样每个节点要么控制子 CGroup 的 Controller 开关(中间节点),要么控制其下 Tasks 的资源配置(叶子节点),结构更清晰。
另外,CGroup V2 去掉了 Tasks 文件,增加了 cgroup.threads 文件,用于管理 LWP(仍然没有放弃对”线程”的支持),但语义上会清晰一些。
站在进程的角度来说,在挂载 CGroup V2时,所有已有Live Proc PID 都会加入到 Root CGroup,之后所有新创建的进程都会自动加入到父进程所属的 CGroup,由于 V2 只有一个 Hierarchy,因此一个进程同一时间只会属于一个 CGroup:
root# cat /proc/842/cgroup
...
0::/test-cgroup/test-cgroup-nested
总的来说,CGroup V2去掉了多个 Hierarchy 结构,使用 unified Hierarchy,对 Hierarchy 内部层级结构作出一些限制以保证层级逻辑清晰,并且优化了 CGroup 的文件组织(如 cgroup.events, cgroup.threads)。由于目前手头暂时没有 Kernel 4.5,只能通过文档大概了解下,还是要找机会实际体验一下。
Reference: