简单介绍一下Erlang常用数据结构的内部实现和特性,主要参考Erlang OTP 18.0源码,和网上很多优秀博客(参见附录),整理了一些自己项目中常用到的。
Erlang虚拟机使用一个字(64/32位)来表示所有类型的数据,即Eterm。具体的实施方案通过占用Eterm的后几位作为类型标签,然后根据标签类型来解释剩余位的用途。这个标签是多层级的,最外层占用两位,有三种类型:
- 01: list,剩下62位是指向列表Cons的指针
- 10: boxed对象,即复杂对象,剩余62位指向boxed对象的对象头。包括元组,大整数,外部Pid/Port等
- 11: immediate立即数,即可以在一个字中表示的小型对象,包括小整数,本地Pid/Port,Atom,NIL等
这三种类型是Erlang类型的大框架,前两者是可以看做是引用类型,立即数相当于是值类型,但无论对于哪种类型,Erlang Eterm本身只占用一个字,理解这一点是很重要的。
对于二三级标签的细分和编码,一般我们无需知道这些具体的底层细节,以下是几种常用的数据结构实现方式。
一. 常用类型
1. atom
atom用立即数表示,在Eterm中保存的是atom在全局atom表中的索引,依赖于高效的哈希和索引表,Erlang的atom比较和匹配像整数一样高效。atom表是不回收的,并且默认最大值为1024*1024,超过这个限制Erlang虚拟机将会崩溃,可通过+t参数调整该上限。
2.Pid/Port
/* erts/emulator/beam/erl_term.h
*
* Old pid layout(R9B及之前):
*
* +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
* |s s s|n n n n n n n n n n n n n n n|N N N N N N N N|c c|0 0|1 1|
* +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
*
* s : serial 每次n到达2^15之后 自增一次 然后n重新从低位开始
* n : number 15位, 进程在本地进程表中的索引
* c : creation 每次节点重启,该位自增一次
* N : node number 节点名字在atom表中索引
*
*
* PID layout (internal pids):
*
* +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
* |n n n n n n n n n n n n n n n n n n n n n n n n n n n n|0 0|1 1|
* +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
*
* n : number 28位进程Pid
*/
在Old Pid表示中(R9B及之前版本),在32位中表示了整个Pid,包括其节点名字等信息,也就是本地进程和外部进程都可以用Eterm立即数表示,显示格式为<N, n, s>。
在R9B之后,随着进程数量增加和其它因素,Pid只在32位中表示本地Pid(A=0),将32位中除了4位Tag之外的28位,都可用于进程Pid表示,出于Pid表示的历史原因,仍然保留三段式的显示,本地Pid表示变成了<0, Pid低15位, Pid高13位>。对于外部Pid,采用boxed复合对象表示,在将本地Pid发往其它node时,Erlang会自动将为Pid加上本地节点信息,并打包为一个boxed对象,占用6个字。另外,Erlang需要维护Pid表,每个条目占8个字节,当进程数量过大时,Pid表将占用大量内存,Erlang默认可以使用18位有效位来表示Pid(262144),可通过+P参数调节,最大值为27位(2^27-1),此时Pid表占用内存为2G。
1 | Eshell V8.1 (abort with ^G) |
3. lists
列表以标签01标识,剩余62位指向列表的Cons单元,Cons是[Head|Tail]的组合,在内存中体现为两个相邻的Eterm,Head可以是任何类型的Eterm,Tail是列表类型的Eterm。因此形如L2 = [Elem|L1]的操作,实际上构造了一个新的Cons,其中Head是Elem Eterm,Tail是L1 Eterm,然后将L2的Eterm指向了这个新的Cons,因此L2即代表了这个新的列表。对于[Elem|L2] = L1,实际上是提出了L1 Eterm指向的Cons,将Head部分赋给Elem,Tail部分赋给L2,注意Tail本身就是个List的Eterm,因此list是单向列表,并且构造和提取操作是很高效的。需要再次注意的是,Erlang所有类型的Eterm本身只占用一个字大小。这也是诸如list,tuple能够容纳任意类型的基础。
Erlang中进程内对对象的重复引用只需占用一份对象内存(只是Eterm本身一个字的拷贝),但是在对象跨进程时,对象会被展开,执行速深度拷贝:
1 | Eshell V7.0.2 (abort with ^G) |
此时L1, L2的内存布局如下:
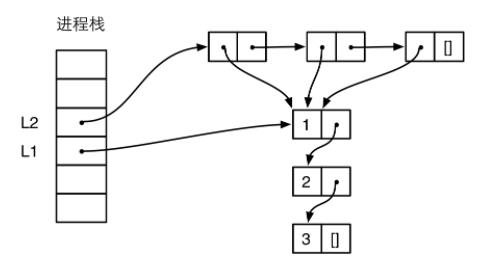
4. tuple
tuple属于boxed对象的一种,每个boxed对象都有一个对象头(header),boxed Eterm即指向这个header,这个header里面包含具体的boxed对象类型,如tuple的header末6位为000000,前面的位数为tuple的size:

tuple实际上就是一个有头部的数组,其包含的Eterm在内存中紧凑排列,tuple的操作效率和数组是一致的。
list和tuple是erlang中用得最多的数据结构,也是其它一些数据结构的基础,如record,map,摘下几个关于list,tuple操作的常用函数,便于加深对结构的理解:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51// 位于 $OTP_SRC/erts/emulator/beam/bif.c
BIF_RETTYPE tuple_to_list_1(BIF_ALIST_1)
{
Uint n;
Eterm *tupleptr;
Eterm list = NIL;
Eterm* hp;
if (is_not_tuple(BIF_ARG_1)) {
BIF_ERROR(BIF_P, BADARG);
}
// 得到tuple Eterm所指向的tuple对象头
tupleptr = tuple_val(BIF_ARG_1);
// 得到对象头中的tuple size
n = arityval(*tupleptr);
hp = HAlloc(BIF_P, 2 * n);
tupleptr++;
// 倒序遍历 因为list CONS的构造是倒序的
while(n--) {
// 相当于hp[0]=tupleptr[n]; hp[1] = list; list = make_list(hp);
// 最后返回的是指向hp的list Eterm
list = CONS(hp, tupleptr[n], list);
hp += 2;
}
BIF_RET(list);
}
BIF_RETTYPE list_to_tuple_1(BIF_ALIST_1)
{
Eterm list = BIF_ARG_1;
Eterm* cons;
Eterm res;
Eterm* hp;
int len;
if ((len = erts_list_length(list)) < 0 || len > ERTS_MAX_TUPLE_SIZE) {
BIF_ERROR(BIF_P, BADARG);
}
// 元素个数 + 对象头
hp = HAlloc(BIF_P, len+1);
res = make_tuple(hp);
*hp++ = make_arityval(len);
while(is_list(list)) {
cons = list_val(list);
*hp++ = CAR(cons);
list = CDR(cons);
}
BIF_RET(res);
}
可以看到,list,tuple中添加元素,实际上都是在拷贝Eterm本身,Erlang虚拟机会追踪这些引用,并负责垃圾回收。
5. binary
Erlang binary用于处理字节块,Erlang其它的数据结构(list,tuple,record)都是以Eterm为单位的,用于处理字节块会浪费大量内存,如”abc”占用了7个字(加上ETerm本身),binary为字节流提供一种操作高效,占用空间少的解决方案。
之前我们介绍的数据结构都存放在Erlang进程堆上,进程内部可以使用对象引用,在对象跨进程传输时,会执行对象拷贝。为了避免大binary跨进程传输时的拷贝开销,Erlang针对binary作出了优化,将binary分为小binary和大binary。
heap binary
小于64字节(定义于erl_binary.h ERL_ONHEAP_BIN_LIMIT宏)的小binary直接创建在进程堆上,称为heap binary,heap binary是一个boxed对象:
1 | typedef struct erl_heap_bin { |
refc binary
大于64字节的binary将创建在Erlang虚拟机全局堆上,称为refc binary(reference-counted binary),可被所有Erlang进程共享,这样跨进程传输只需传输引用即可,虚拟机会对binary本身进行引用计数追踪,以便GC。refc binary需要两个部分来描述,位于全局堆的refc binary数据本身和位于进程堆的binary引用(称作proc binary),这两种数据结构定义于global.h中。下图描述refc binary和proc binary的关系:
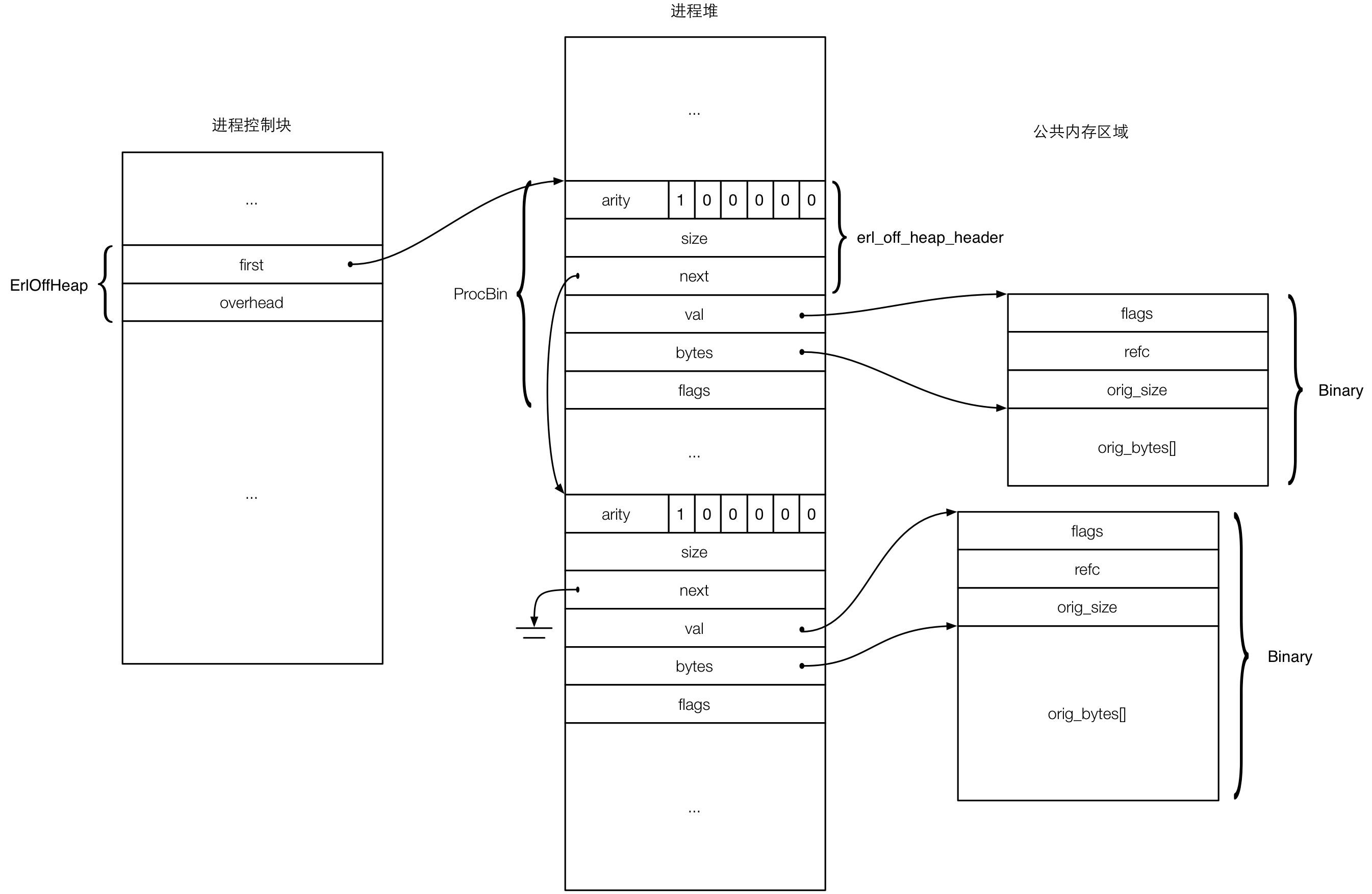
所有的OffHeap(进程堆之外的数据)被组织为一个单向链表,进程控制块(erl_process.h struct process)中的off_heap字段维护链表头和所有OffHeap对象的总大小,当这个大小超过虚拟机阀值时,将导致一次强制GC。注意,refc binary只是OffHeap对象的一种,以后可扩展其它种类。
sub binary
sub binary是Erlang为了优化binary分割的(如split_binary/2),由于Erlang变量不可变语义,拷贝分割的binary是效率比较底下的做法,Erlang通过sub binary来复用原有binary。ErlSubBin定义于erl_binary.h,下图描述split_binary(ProBin, size1)返回一个ErlSubBin二元组的过程:
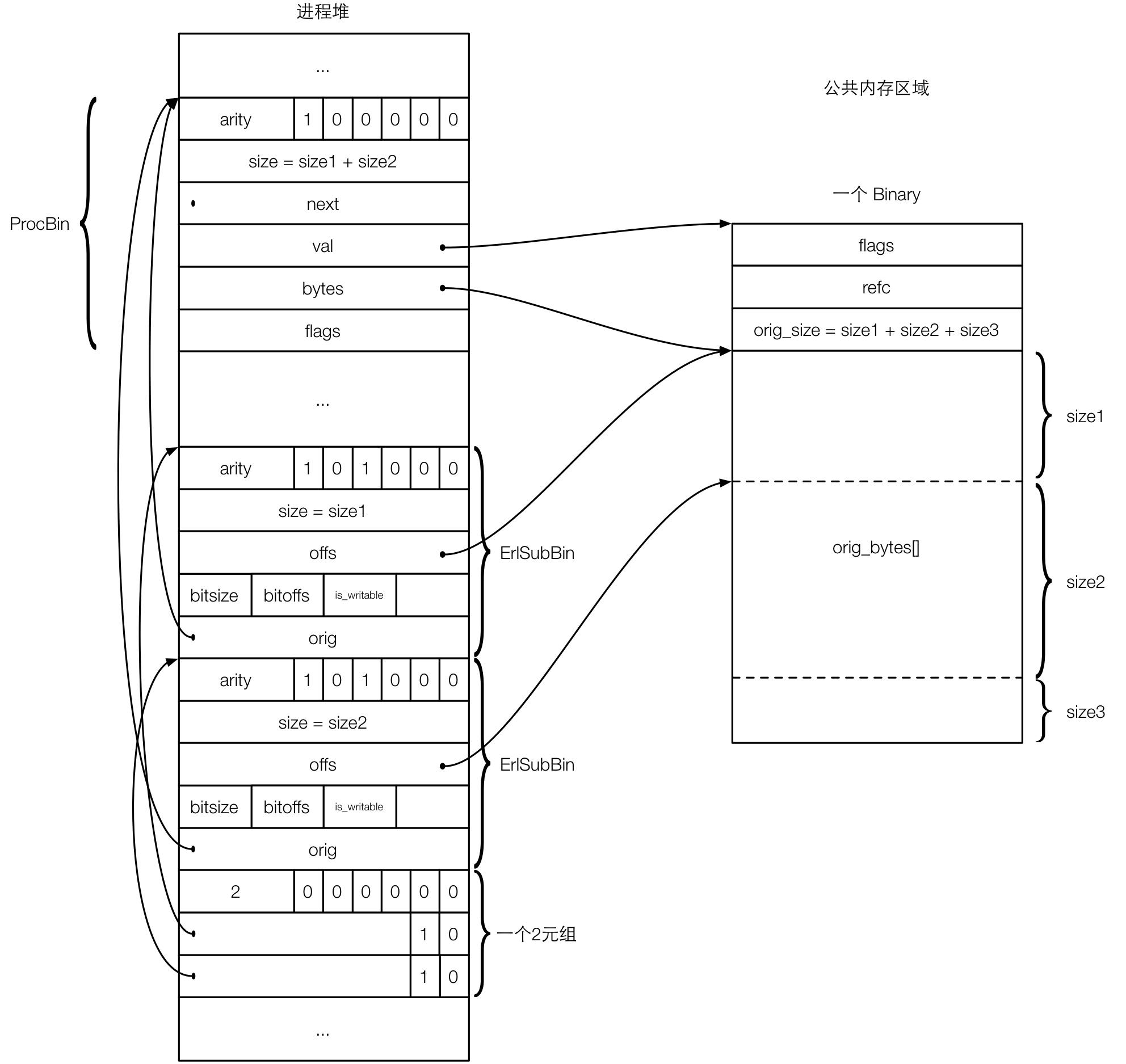
ProBin的size可能小于refc binary的size,如上图中的size3,这是因为refc binary通常会通过预分配空间的方式进行优化。
要注意的是,sub binary只引用proc binary(通过orig),而不直接引用refc binary,因此图中refc binary的refc字段仍然为1。只要sub binary还有效,对应的proc binary便不会被GC,refc binary的计数也就不为0。
bit string
当我们通过如<<2:3,3:6>>的位语法构建binary时,将得到<<65,1:1>>这种非字节对齐的数据,即二进制流,在Erlang中被称为bitstring,Erlang的bitstring基于ErlSubBin结构实现,此时bitsize为最后一个字节的有效位数,size为有效字节数(不包括未填满的最后一个字节),对虚拟机底层来说,sub bianry和bit string是同一种数据结构。
binary追加构造优化
在通过C = <<A/binary,B/binary>>追加构造binary时,最自然的做法应当是创建足够空间的C(heap or refc),再将A和B的数据拷贝进去,但Erlang对binary的优化不止于此,它使用refc binary的预留空间,通过追加的方式提高大binary和频繁追加的效率。
1 | Bin0 = <<0>>, %% 创建一个heap binary Bin0 |
binary追加实现源码位于$BEAM_SRC/erl_bits.c erts_bs_append,B1和B2本身是sub binary,基于同一个ProcBin,可追加的refc binary只能被一个ProcBin引用,这是因为可追加refc binary可能会在追加过程中重新分配空间,此时要更新ProcBin引用,而refc binary无法快速追踪到其所有ProcBin引用(只能遍历),另外,多个ProcBin上的sub binary可能对refc binary覆写。
只有最后追加得到的sub binary才可执行快速追加(通过sub binary和对应ProBin flags来判定),否则会拷贝并分配新的可追加refc binary。所有的sub binary都是指向ProcBin或heap binary的,不会指向sub binary本身。
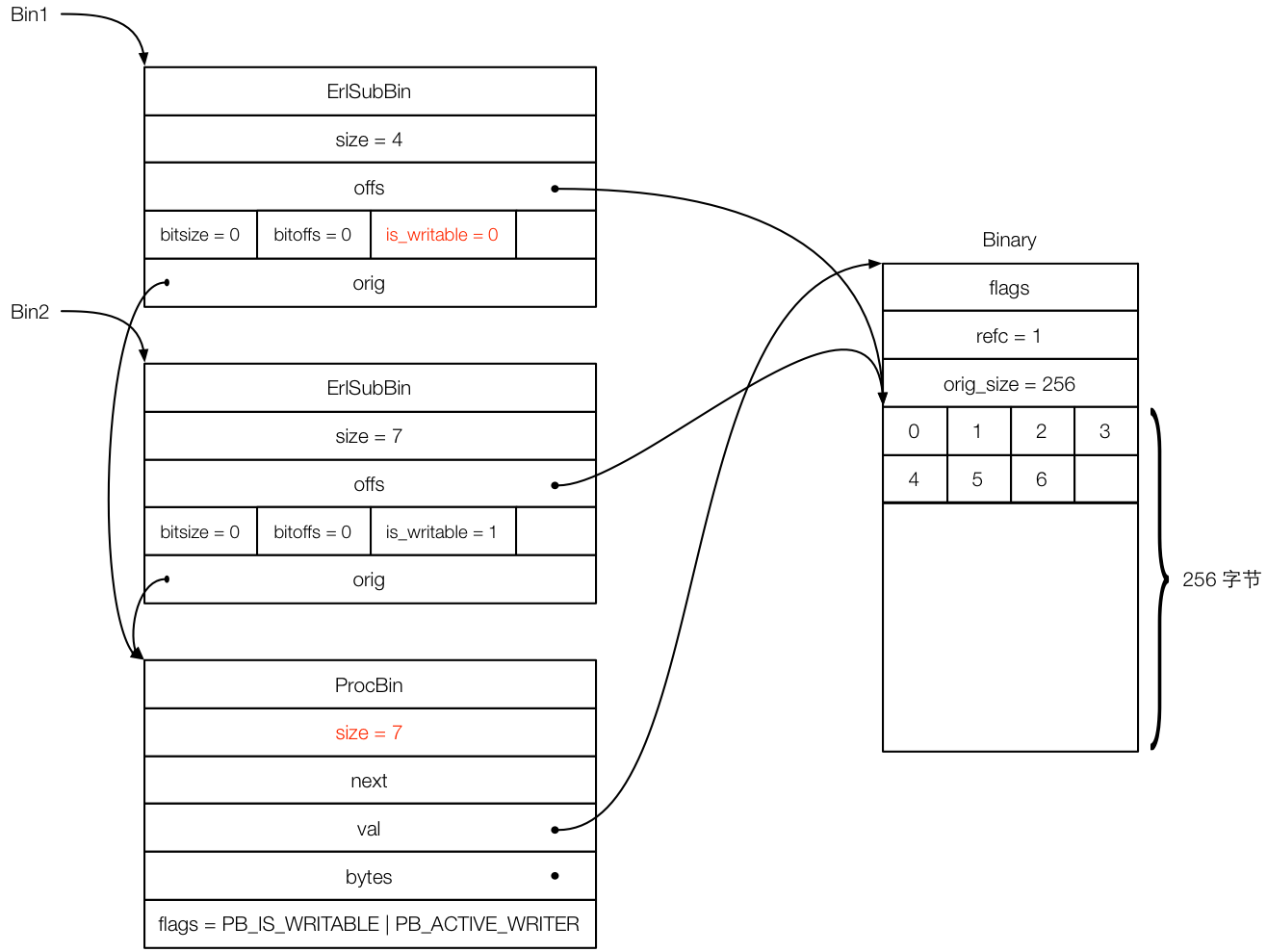
binary降级
Erlang通过追加优化构造出的可追加refc binary通过空间换取了效率,并且这类refc binary只能被一个proc binary引用(多个proc binary上的sub binary会造成覆写,注意,前面的B1,B2是sub binary而不是ProBin)。比如在跨进程传输时,原本只需拷贝ProBin,但对可追加的refc binary来说,不能直接拷贝ProBin,这时需对binary降级,即将可追加refc binary降级为普通refc binary:
bs_emasculate(Bin0) ->
Bin1 = <<Bin0/binary, 1, 2, 3>>,
NewP = spawn(fun() -> receive _ -> ok end end),
io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]),
NewP ! Bin1,
io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]),
Bin2 = <<Bin1/binary, 4, 5, 6>>, % Bin1被收缩 这一步会执行refc binary拷贝
io:format("Bin2 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin2})]),
Bin2.
% 运行结果
117> bs_emasculate(<<0>>).
Bin1 info: {refc_binary,4,{binary,256},3}
Bin1 info: {refc_binary,4,{binary,4},0}
Bin2 info: {refc_binary,7,{binary,256},3}
<<0,1,2,3,4,5,6>>
降级操作会重新创建一个普通的refc binary(原有可追加refc binary会被GC?),同时,降级操作会将B1的flags置0,这保证基于B1的sub binary在执行追加时,会重新拷贝分配refc binary。
// 降级函数($BEAM_SRC/erl_bits.c)
void erts_emasculate_writable_binary(ProcBin* pb)
{
Binary* binp;
Uint unused;
pb->flags = 0;
binp = pb->val;
ASSERT(binp->orig_size >= pb->size);
unused = binp->orig_size - pb->size;
/* Our allocators are 8 byte aligned, i.e., shrinking with
less than 8 bytes will have no real effect */
if (unused >= 8) {
// 根据ProBin中的有效字节数,重新创建一个不可追加的refc binary
binp = erts_bin_realloc(binp, pb->size);
pb->val = binp;
pb->bytes = (byte *) binp->orig_bytes;
}
}
Q: ProcBin B1的字段被更新了,那么Erlang上层如何维护变量不可变语义?
A: 变量不可变指的是Erlang虚拟机上层通过底层屏蔽后所能看到的不变语义,而不是变量底层实现,诸如Pid打包,maps hash扩展等,通过底层差异化处理后,对上层体现的语义和接口都没变,因此我们将其理解为”变量不可变”)。
另外,全局堆GC也可能会对可追加refc binary的预留空间进行收缩(shrink),可参考$BEAM_SRC/erl_gc.c sweep_off_heap函数。
以上都是理论的实现,实际上Erlang虚拟机对二进制还做了一些基于上下文的优化,通过bin_opt_info编译选项可以打印出这些优化。关于binary优化的更多细节,参考Constructing and Matching Binaries。
二. 复合类型
基于list和tuple之上,Erlang还提供了一些其它的数据结构,这里列举几个key/value相关的数据结构,在服务器中会经常用到。
1. record
这个类型无需过多介绍,它就是一个tuple,所谓record filed在预编译后实际上都是通过数值下标来索引,因此它访问field是O(1)复杂度的。
2. map
虽然record的语法糖让我们在使用tuple时便利了不少,但是比起真正的key/value结构仍然有许多限制,如key只能是原子,key不能动态添加或删除,record变动对热更的支持很差等。proplists能够一定程度地解决这种问题,但是它适合键值少的情况,通常用来做选项配置,并且不能保证key的唯一。
map是OTP 17引进的数据结构,是一个boxed对象,它支持任意类型的Key,模式匹配,动态增删Key等,并且最新的mongodb-erlang直接支持map。
在OTP17中,map的内存结构为:
1 | //位于 $OTP_SRC/erts/emulator/beam/erl_map.h |
该结构体之后就是依次存放的Value,因此maps的get操作,需要先遍历keys tuple,找到key所在下标,然后在value中取出该下标偏移对应的值。因此是O(n)复杂度的。详见maps:get源码($BEAM_SRC/erl_map.c erts_maps_get)。
如此的maps,只能作为record的替用,并不是真正的Key->Value映射,因此不能存放大量数据。而在OTP18中,maps加入了针对于big map的hash机制,当maps:size < MAP_SMALL_MAP_LIMIT时,使用flatmap结构,也就是上述OTP17中的结构,当maps:size >= MAP_SMALL_MAP_LIMIT时,将自动使用hashmap结构来高效存取数据。MAP_SMALL_MAP_LIMIT在erl_map.h中默认定义为32。
仍然要注意Erlang本身的变量不可变原则,每次执行更新maps,都会导致新开辟一个maps,并且拷贝原maps的keys和values,在这一点上,maps:update比maps:put更高效,因为前者keys数量不会变,因此无需开辟新的keys tuple,拷贝keys tuples ETerm即可。实际使用maps时:
- 更新已有key值时,使用update(:=)而不是put(=>),不仅可以检错,并且效率更高
- 当key/value对太多时,对其进行层级划分,保证其拷贝效率
实际测试中,OTP18中的maps在存取大量数据时,效率还是比较高的,这里有一份maps和dict的简单测试函数,可通过OTP17和OTP18分别运行来查看效率区别。通常情况下,我们应当优先使用maps,比起dict,它在模式匹配,mongodb支持,可读性上都有很大优势。
3. array
Erlang有个叫array的结构,其名字容易给人误解,它有如下特性:
- array下标从0开始
- array有两种模式,一种固定大小,另一种按需自动增长大小,但不会自动收缩
- 支持稀疏存储,执行array:set(100,value,array:new()),那么[0,99]都会被设置为默认值(undefined),该默认值可修改。
在实现上,array最外层被包装为一个record:
1 | -record(array, { |
elements是一个tuple tree,即用tuple包含tuple的方式组成的树,叶子节点就是元素值,元素默认以10个为一组,亦即完全展开的情况下,是一颗十叉树。但是对于没有赋值的节点,array用其叶子节点数量代替,并不展开:
1 | Eshell V7.0.2 (abort with ^G) |
由于完全展开的tuple tree是一颗完全十叉树,因此实际上array的自动扩容也是以10为基数的。在根据Index查找元素时,通过div/rem逐级算出Index所属节点:
1 | %% 位于$OTP_SRC/lib/stdlib/src/array.erl |
更多细节可以参见源码,了解了这些之后,再来看看Erlang array和其它语言数组不一样的地方:
- 索引不是O(1)复杂度,而是O(log10n)
- array并不自动收缩
- array中的max和size字段,和array具体占用内存没多大关系(节点默认未展开)
- array中并没有subarray之类的操作,因为它根本不是线性存储的,而是树形的,因此如果用它来做递归倒序遍历之类的操作,复杂度不是O(n),而是O(n*log10n)
- array中对于没有赋值的元素,给予默认值undefined,这个默认值可以在array:new()中更改,对使用者来说,明确赋值undefined和默认值undefined并无多大区别,但对array内部来说,可能会导致节点展开。
三. 参考
- Erlang数据结构实现文章汇总: http://www.iroowe.com/erlang_eterm_implementation/
- [zhengsyao] Erlang系列精品博客(文中大部分图片出处): http://www.cnblogs.com/zhengsyao/category/387871.html
- [坚强2002] Erlang array: http://www.cnblogs.com/me-sa/archive/2012/06/14/erlang-array.html
- Erlang Effciency Guide: http://erlang.org/doc/efficiency_guide/introduction.html