如果给你一个服务器框架,你如何评估这个框架?不同的人可能有不同的维度和优先级,比如性能,可维护性,可扩展性,可用性,可靠性等等等等,目前已经有相对成熟的几种软件质量评估方案。其中McCall软件评估模型(1977)比较有意思:
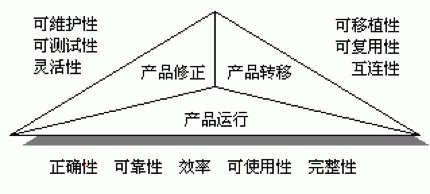
产品修正: 开发视角,反映系统应对变更的能力
产品运行: 用户视角,产品稳定性,效率,易用性等
产品转移: 运维视角,可移植性,组件复用性等
对于服务器而言,有跨平台语言和Docker等技术的加持,产品转移已经变得非常容易,我这里主要结合项目实践以及对Go和Erlang的一些理解,谈谈产品修正中的可扩展性/可维护性以及产品运行中的可靠性。
一. 可维护性/可扩展性
反映软件适应“变化”的能力。调整、修改或改进正在运行的软件系统以适应新需求或者需求变更的难易程度。
正交设计
要达成可扩展性,正交是一个非常重要的概念,一个可扩展性好的系统必定是正交的。关于正交,我找到一个很好的例子来帮助理解:
非正交代码:
| 客户需求 | 代码实现 |
|---|---|
| (1 2 3) | (1 2 3) |
| (6 5 4) | (1 2 3)+(5 3 1)=(6 5 4) |
| (3 6 9) | (6 5 4)+(-3 1 5)=(3 6 9) |
正交代码:
x = (1 0 0)
y = (0 1 0)
z = (0 0 1)
| 客户需求 | 代码实现 |
|---|---|
| (1 2 3) | x+2y+3z |
| (6 5 4) | 6x+5y+4z |
| (3 6 9) | 3x+6y+9z |
正交是软件工程中非常重要的一个概念,它将一个系统拆分为多个互不依赖的维度,每个维度可以独立变化,整个系统变得更容易理解。正交的优点很多,比如易于测试,维护,可复用程度高,更能够适应变化等等。在我看来,绝大部分软件设计理念都是围绕如何更好地拆分系统,达成正交而产生的,比如面向对象的设计模式,MVC,消息中间件,微服务架构等等,都是从不同的角度来达成软件的正交性。
正交的基本手段仍然是封装和解耦,复用,只是说封装角度(功能模块,公用流程,变化程度等),解耦方式(组合,中间件,RPC等),以及复用粒度(函数,类,组件,节点等)的区别,比如设计模式,重点讲的是在类级别上,如何封装变化和解耦依赖,MVC侧重封装的角度(按照变更特性),消息中间件侧重解耦的方式,微服务则侧重解耦(服务发现)和复用粒度(服务)。
正交实践
以下是一些项目中的正交实践:
- 正交支持: Func,Package,Actor,Node,后两者由框架提供
- 正交复用: 复用基本流程,如Actor, DB序列化,Gate等
- 正交解耦: 解耦组件依赖,如EventMgr,RabbitMQ,Etcd等
- 正交变化: 以变化特性进行拆分,如Controller/Model,以及战斗配置等
- 持续重构: 开发中对重复敏感,对变化敏感,适当运用设计模式,常用的如观察者模式,控制反转,策略模式等等
正交不只是一个设计目标,也是一个重构目标,它会随着系统功能和需求的迭代而变更,就像微服务一样,粒度过细则可能过犹不及。
二. 可靠性
可靠性通常分为两个方面:健壮性(鲁棒性)和容错性。
- 健壮性: 是指一个计算机系统在执行过程中处理错误,以及算法在遭遇输入、运算等异常时继续正常运行的能力。
- 容错性: 是使系统在部分组件(一个或多个)发生故障时仍能正常运作的能力。
健壮性是指系统是对外部输入的处理能力,你按照我的调用规范来使用系统,系统会正常返回,如果你不按照我的调用规范来使用系统,系统返回给你错误,但是系统本身不会Down掉。因此健壮性更多地是强调错误预防,而容错性是指当系统内部错误发生之后,如何处理错误和进行错误恢复。
1. 健壮性
防御式编程
提到错误,不得不提一下防御式编程:
你写的代码,应该考虑到所有可能发生的错误,让你的程序不会因为他人的错误而发生错误。
我认为部分同学对防御式编程是有误解的,将其简单理解成了不让服务器崩溃,在实践中,有些同学为了方便,可能会忽略对错误的处理(反正有defer),或者简单打个Log,而不去认真思考这个错误意味着什么,后续逻辑应该怎么处理,这个错误如何反馈给调用方等等,这往往会给系统带来更多的不确定性,并且在错误发生时难以调试。
举个简单的例子,我们的Pf模块,负责和平台进行交互,屏蔽HTTP通信,Token管理,服务地址等细节,我们有个API,用于向平台获取角色列表,这个API在获取到角色列表对其进行解析时,其中一个角色元信息Json解析出错了(简单认为不可能出错),如果你忽略了这个错误,或者只是简单打个日志,然后跳过这个角色解析,最终逻辑模块将以为一切正常,然后交给客户端,客户端就找不到这个角色了,甚至再发起创建角色流程。
防御式编程强调的是尽可能地考虑并且处理能够预料到的错误,而不是说隐藏或者忽略意料之外的错误,对于不能Handle的错误,该传给调用方传给调用方,该终止服务器就终止。
在实践中,需要设计和使用API时,重视error规范,认真考虑各种异常输入和错误返回等。
测试
关于测试的问题,我们之前有过探讨了,关于测试的好处和难点这里不再赘述。在项目实践中,我比较推崇API测试和测试用例,前者是白盒测试,结合go test规范,用于底层不常变的基础设施测试,后者是黑盒测试,用于功能性测试,其它更详尽的测试个人认为是不适用于游戏的。
另外为了更好地测试,可以结合开发环境的特性,特例化开发环境配置,比如适当调小模块Channel大小(让错误更早暴露出来),对一些关键性错误直接Panic(比如消息未注册),另外,也可以结合一些语言提供的工具,比如通过-race参数来检查竞态(非常吃内存和性能,不建议线上使用),通过常驻的http pprof工具提供实时地内存,性能和死锁分析等。
2. 容错能力
容错能力分为三个层面:错误隔离,错误处理,错误恢复。
谈到容错,我想不得不提的就是Erlang,Erlang提供了错误隔离,处理,恢复一条龙服务,进程出错(不会影响到其它进程,错误隔离),进入terminal函数(错误处理),监督者监控到子进程Crash,尝试重启(错误恢复)。
和防御式编程一样,Erlang的Let it Crash,也是个容易误解的概念,它不是说鼓励崩溃,而是说不怕崩溃,Erlang认为你不可能提前预知到所有错误,因此它对错误做最坏的打算,得益于Erlang的Actor模型和错误隔离机制,能够最大程度地控制崩溃的影响范围,因此它可以基于自己的轻量化,帮你尝试做错误恢复。因此反过来讲,正因为其它语言没有像Erlang这样强大的容错能力,因此他们在错误处理上面如履薄冰,鼓励你更多地从错误预防的角度考虑,而Erlang允许你偷懒,写更少的防御代码,它的错误处理和恢复帮你擦屁股。另外,Erlang并不是无脑帮你重启进程,Erlang的错误恢复基于如下三点背景:
- 良好的Actor模型实践,保证Crash的影响范围小,比如单个玩家
- 大部分的错误可以通过重启恢复(没有什么是重启不能解决的?)
- 进程监督者会设置重启上限
Go语言只给开发者错误捕获机制,错误隔离都需要捕获错误才能够完成。但我们仍然可以从Erlang Actor模型中借鉴学习到一些东西,具体到实践中:
- Go in Actor: 原生goroutine的使用是比较有风险的(mem leak,deadlock,panic等),框架上应该封装逻辑goroutine(相当于actor),统一管理actor的消息队列/交互/顺序依赖等,避免逻辑层对原生goroutine的使用(比如提供一个worker pool,毕竟逻辑层大部分时候只是想要个可以异步执行任务的地方)
- defer但不是无限制defer actor error,特别对于逻辑模块,defer打印堆栈信息,但要对错误进行阈值设定,一个进一步的尝试是通过actor当前上下文对错误进行分类统计(主要针对大粒度的Actor)
- 异步思维是构建高容错系统的必备思维,一个通用的实践是,将所有的外部IO封装成模块,IO模块对所有同步IO操作设置超时(context, deadline),其它模块与IO模块间异步交互。此外,逻辑模块之间也应该限制对同步调用的使用,防止死锁和并发瓶颈
3. 可调试能力
可调试能力本身不是可靠性的一部分,这里我把它作为一种错误诊断手段,一并补在这里,Go语言没有像Erlang那种强大的动态调试能力(无痛DEBUG),也没有热更,因此框架方面需要考虑到这方面的支持,方面快速定位BUG&修复数据。
实践:
- 模拟机器人: 提供一个客户端的Console模拟,用于灵活地向服务器构建&发送消息,用于黑盒测试。
- 后台Console: 一些状态Debug和GM命令,比如查看各个模块的异步调用状态,PProf数据,刷新大地图NPC等等。
- Lua脚本: 可以拉取一些服务器内部数据状态,比如玩家数据,并对其进行简单修改。
- PProf: 通过http pprof或者配合Console拿到pprof数据,也能对当前系统状态有一份不错的参考,特别针对与死锁或者性能问题,具体使用参考