这段时间学习OOP对语言和编程范式有一些新的理解,之前系统整理过函数式编程,因此先从OOP谈起。我们先回顾下面向对象(OOP)的核心思想:
- 所有的值都是对象
- 对象与对象之间通过方法调用(或者说是发消息)进行通信
- 对象可以有自己的私有字段/状态,只有对象的方法可以访问和更新这些字段
- 每个对象都是一个类(Class)的实例,类定义了对象的行为(内部数据和方法实现)
与函数式的”一切皆函数”一样,OOP也有一个宏大的目标”一切皆对象”。
oop with dynamic type
动态OOP语言,以Ruby为例,它是一种”纯度比较高”的OOP语言,它有一些比较有意思的特性:
- null,3,true等都是对象,对象的类也是对象,当然也有例外,如Blocks
- 由于对象的类也是对象(类型为Class),因此你可以像更改对象一样动态更改类的定义,如添加新方法
- 对象与对象之间只能通过方法通信,即对象不能直接访问其它对象的字段
subclass
除了基于对象的封装之外,另一个OOP需要考虑的问题就是复用,以Ruby为例,比如我们有个Point类:
1 | class Point |
现在我们要创建一个ColorPoint类,它除了多个Color字段外,其它属性和行为与Point一模一样,这个时候我们有以下几种做法:
- 在ColorPoint类定义中,将Point相关的代码拷贝过来或重写,ColorPoint成为了与Point不相关的两个类
- 在ColorPoint类中定义一个Point类的成员,然后将distFromOrigin和distFromOrigin2等方法都转调(forwarding)到该成员上
- 通过将ColorPoint声明为Point的子类(subclass),这样ColorPoint就继承Point的所有属性和方法,并且仍然可以自己扩展属性,覆盖或新增方法
以上三种实现方式导致的ColorPoint和Point耦合度依次递增,在大多数场景下,该问题的最佳方案应该是方案3,因为它能够最大程度达成代码复用,并且在此例子,ColorPoint “is-a” Point。
但是,在OOP中,subclass通常是很容易被过度使用,比如我们现在要实现一个Point3D类,它多了个z属性,那么它的distFromOrigin和distFromOrigin2都需要override,它真正能够复用的只有x,y两个存取器,这个时候就会有一些争议(复用程度太低),特别是如果Point还有个方法distance(p),用于求出两点距离时,此时Point3D需要override该方法,并且参数为Point3D,此时将Point对象传给Point3D的distance将得到运行时错误。因此在用subclass时,需要谨慎评估类之间的关系,以及类扩展和重写带来的影响。
duck typing
由于Ruby是动态语言,前面我们讨论的ColorPoint的三种实现方式都不影响ColorPoint和Point的使用,如我们有个函数:
1 | def mirror_update pt |
三种方式实现的ColorPoint都可以作为mirror_update的参数,因为mirror_update对参数pt的要求是:
- pt实现了
x()方法 pt.x()方法的返回值实现了*方法,可接受-1为参数- pt实现了
x=方法,可接受pt.x*-1的结果作为参数
三种方式实现的Point和ColorPoint都满足以上要求,因此它们都可以使用mirror_update函数。这就是所谓的Duck Typing。在Ruby这类动态类型OOP语言中,代码复用非常灵活。当然这也不是免费的,由于少了静态类型检查,如果调用mirror_update(Point.new(1,"haha"))会”正确”得到-1,而调用mirror_update(Point.new("haha",-1))则会得到negative argument (ArgumentError)运行时错误(string没有实现*方法),两种调用报错的时机和报错的形式取决与业务代码。尽管它们从逻辑上来说都是错误的。
dynamic dispatch
再举一个例子,如果我们要以subclass创建一个极坐标点类PolarPoint(包含一个半径属性和一个角度属性),为了保证继承的语义,PolarPoint不得不重写来自于Point的x,y属性,我们不再讨论这里使用继承的合理性,而是想引出一个有意思的地方: PlarPoint的distFromOrigin2无需重写,已经可以正常工作!这得益于ruby的dynamic dispatch: 用subclass的对象调用superclass的方法时,将优先动态dispatch到subclass的方法上。dynamic dispatch在其它语言中也叫做虚函数(virtual function)或延迟绑定(late bingding),核心思路是基于对象的方法调用,总是优先从对象实际所属类(动态)上动态查找,而不是方法所属类(静态)。
dynamic dispatch让代码复用更上了一个层次,比如你可能有一些GUI相关的基类,它已经实现绘图,缩放等操作,你在子类中只需要实现必要的形状信息,就可以基类的方法绘制定制图形,而无需自己再重写绘图相关操作。
mutiple inheritance
回到我们的ColorPoint,随着功能迭代,ColorPoint的颜色相关API越来越多,如加深/调色等,你可能希望将这部分代码单独抽象为一个Color类,以达成更好的代码复用。然后ColorPoint再从Color类和Point类继承,这就是多重继承。在OOP中,多重继承的名声不是太好,因为它有一些”哲学上的问题”无法达成统一: 当两个superclass有相同的字段和方法时,subclass应该如何继承?
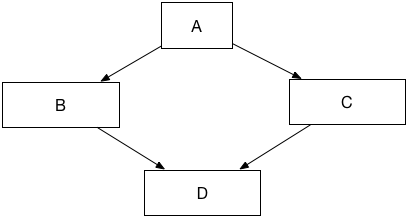
假如B和C有相同的属性和方法,那么有如下可能:
- D希望同时继承B和C的同名方法: 即D同时有B和C的能力,这是继承的本意,名字碰撞应该通过其它作用域来限制
- D希望只继承B或C的方法: 比如B为ColorPoint,C为Point3D,D为ColorPoint3D,那么显然,D应该继承C的distFromOrigin方法
- B,C相同的方法在A中也有,D想直接从A中继承…
这就像在现实中,子女的长相可能随父亲,身高可能随母亲,脾气可能谁也不像。多重继承的这些问题很容易造成歧义和理解负担。Ruby选择不支持多重继承,但提供一个叫mixins的机制: 尝试通过include module的方式来消除对多重继承的需要。比如ColorPoint:
1 | module Color |
module和class的主要区别在于它不能实例化对象且不能派生子类,它可以有属性,但用得更多地场景是它只提供方法,然后引用一些它本身未定义的方法交给子类去实现(当然,这里又要用到dynamic dispatch),比如Ruby的Enumerable模块:
1 | class MyRange |
包含Enumerable的class只需要实现each方法,即可调用MyRange.new(4,8).inject {|x,y| x+y},MyRange.new(5,12).count {|i| i.odd?}等方法。mixins通过更像组合(i can)而不是继承(i am)的方式来处理需要多重继承的情形。在方法查找(lookup)规则中,mixins优于subclass,后包含的module优于先包含的。
很多文章说mixins有多重继承的优点,同时也规避了多重继承的问题,我认为mixins的好处非常有限:
- module可以有属性,方法,除了不能实例对象,和普通superclass没有本质区别,也满足
is_a?语义 - module之间,module与superclass仍然有命名冲突的问题,只不过Ruby将lookup规则定死了
- module可以include一个或多个module,这是换了种形式的多重继承
总的来说,由于动态语言的duck typing特性,subclass主要是用在代码复用上,动态语言通常不关心某个对象是否是某个类(或其子类)的实例(is_a?),它只关心某个对象有没有实现某个方法,对方法的查找是基于dynamic dispath的。
oop with static type
聊完动态OOP语言,再来看看静态OOP语言,我们先抛开OOP,静态语言中所有的数据结构,函数参数/返回值都有静态类型,为了阐述方便,我们用伪代码表示某种虚拟的静态语言,它的描述格式为:
1 | // distFromOrigin的参数为两个字段x(类型为double)和y(类型为double)的record(或者叫struct) |
注意,在我们用于举例的语言中,record不只是数据结构的概念,它也可以包含function类型的字段,它可以推广到OOP中的Class。
subtype
现在假设我们有个描述带颜色的点的record: {x:double, y:double, color:string}:
1 | val cp : {x:double,y:double,color:string} = {x=3.0, y=4.0, color="red"} |
而事实上,我们是希望cp能够调用distFromOrigin函数的,因为多color字段既不影响函数计算过程(函数需要的字段都有),也不影响逻辑上的正确性。因此在这里,为了达成更好地代码复用,我们需要静态类型检查做一些扩展: 如果recordA去掉或交换某些字段后变为recordB,那么能用recordB的地方都应该能用recordA。在这种情况下,我们称recordA是recordB的子类型(subtype,注意和子类subclass区分),记 B <: A。有了这个规则后,由于{x:double,y:double,color:string}是{x:double,y:double}的子类型,子类型实参可以匹配父类型形参,因此cp可使用distFromOrigin函数。
depth subtype
现在考虑如下情况,即recordA的某个字段是recordB的某个字段的子类型,那么有recordA<:recordB 吗?听起来是可以的,因为如果一个函数以recordB为形参,那么传入recordA,该函数需要的所有字段都能正确访问到。然而还要考虑到字段可变性:
1 | fun setToOrigin (c:{center:{x:double,y:double}, r:double}) -> |
由于setToOrigin不会知道外部传入的supertype还有哪些额外字段,它对center的重置导致center.z字段丢失了,也就破坏了函数本来的语义。因此通常来说: type checker,field setter,depth subtype只能三选二。
那么实际的编程语言对depth subtype的取舍如何?以Array为例,假如我们有ColorPoint <: Point,那么是否有ColorPoint[] <: Point[]呢?在C++/Go中,是不支持depth subtype的,比如在Go中你不能将[]int实参用于[]interface{}形参(在Go中,interface{}相当于没有任何字段的record,它是任意类型的supertype),因为函数可能将[]interface{}某个元素改为string类型。而在Java/C#中,却是支持的,比如在Java中,以下代码却能静态检查通过正常编译:
1 | class Point { ... } // has fields double x, y |
但是运行时执行m2函数,却会得到ArrayStoreException异常,因为Java/C#选择了可变性和depth subtype,放弃了type checker,放宽了类型检查的限制,它在运行时记录m1中pt_arr的真实类型(ColorPoint[]),并在执行类型不匹配的写入时,抛出异常。
function subtype
这里讨论当函数参数/返回值也是函数,那么这些作为参数的函数的subtype规则。假如我们有如下函数:
1 | fun callWithOrigin(f: {x:double,y:double}->{x:double,y:double}) -> |
callWithOrigin的参数类型为{x:double,y:double}->{x:double,y:double},现在我们来考虑哪些函数实参允许调用callWithOrigin:
{x:double,y:double} -> {x:double,y:double}: ok, 类型完全匹配{x:double,y:double} -> {x:double,y:double,color:string}: ok, callWithOrigin传入f的函数参数匹配,只不过返回的参数多了个color,callWithOrigin可以正常调用和使用f,只不过它不关心返回的color字段{x:double,y:double} -> {x:double}: error, callWithOrigin可能用到f返回值中的y字段{x:double,y:double,z:double} -> {x:double,y:double}: error, callWithOrigin传给f的参数不包含z字段,那么f执行过程就会出错{x:double} -> {x:double,y:double}: ok, callWithOrigin传给f函数的参数包括x,y字段,只是f函数只用到了x,f函数可以正常执行{x:double} -> {x:double,y:double,z:double}: ok,由前面的分析可知,实参函数(即subtype function)参数字段不能多,返回值字段不能少。
因此,有如下结论,对于 t3 <: t1 并且 t2 <: t4, 有 t1->t2 <: t3->t4。
subtype vs subclass
我们在讨论Ruby时用的subclass(子类),而在讨论静态OOP语言时用的是subtype(子类型),因为它们本质上不是一个东西:
- class定义对象的全部行为,subclass是通过继承来解决class与class之间代码复用的问题,子类可以通过重写(override)或扩展(extension)来完善自己的行为
- type关注对象的部分对外接口(字段or方法),subtype用于定义类型之间可替换关系,关注type checker和语义复用
Ruby是动态语言,它有更为灵活的duck typing,因此不需要subtype。对静态语言而言,subtype不一定要通过subclass来实现,理论上你可以有两个完全不相关的类A和B,但他们提供一致的方法,然后你可以声明A是B的subtype。然后任何用B的地方都可以用A。subtype不care这些方法是通过继承得来的还是独立实现的。
但在大多数静态OOP语言,如Java/C#/C++中,type和class的边界很模糊,绝大多数时候,你可以认为它们是一个东西,这是因为这些语言主要依赖subclass来实现subtype,因此当你创建一个class时,相当于创建了一个type,它的名字和class名字一样,当你声明subclass关系时,也声明了subtype关系。
另一点是我们在虚拟语言中以record作为对象的type,这个record可以包含字段,方法等,然后这个record的字段还可以修改,而实际上大多数静态OOP语言中,方法字段是不能修改的,比如你不能拿到一个对象,然后修改它的某个方法,因为方法实现是属于类而不是对象的。
理解了以上两点,我们就能将虚拟语言与现实世界的OOP语言映射起来了,如C++:
- type和class大部分时候是一个东西,声明一个class也就声明了一个type
- subclass可以基于superclass之上添加字段/方法但是不能移除已有字段/方法
- subclass可以override superclass的方法
为了阐述方便,以下探讨C++/Java这类主流编程语言时,不再严格区分subclass和subtype的概念。
dynamic dispath
这里我们进一步讨论静态OOP语言中的dynamic dispatch和this指针,以C++为例:
1 | class Point {}; // include double x, y field |
上面定义了四个类,ColorPoint是Point的subtype,D是B的subtype。以下是一些你需要注意的点:
- 如果D是B的subtype,那么D*也是B*的subtype
- C++中的dynamic dispatch不是默认开启的,而是通过为指定方法
virtual关键字手动开启的 - 对象d上调用showX(声明为virtual)方法,总能找到其对应类D的showX实现,而不管d是否被转换为supertype B*
现在来考虑一个问题,如果B的showX函数声明为virtual void showX(ColorPoint* p),实现不变,那么上面的b->showX(cp)会输出什么?答案是B showX: 3。熟悉C++的同学会知道这是因为C++支持重载,编译认识的函数符号是如_showX_Point_这种编码了参数类型的,修改函数参数类型后,将被编译器认为是另一个函数,而非override。但有一门不支持重载的静态OOP语言L,这个修改能够正常的dynamic dispatch吗?我的理解是可以的,传递给B::showX的ColorPoint总能被D::showX正确使用(D:::showX<:B::showX),这是因为静态OOP语言中的对象不能修改方法(方法属于类),只能修改字段,也就是在前面说的depth subtype中,舍弃了mehotd field setter,得到method field depth subtyping。
然后来看看this指针,对C++有一定理解的同学通常将this指针看做类方法的一个隐藏参数,它由编译器自动传入。这种看法确实能更好地理解OOP,将类方法与普通函数统一起来。但有了subtype这个概念,再来看showX方法,B和D的showX方法类型分别为: void showX(B* this, Point* p) 以及 void showX(D* this, Point* p),这里就出现一个很奇怪的现象,D的showX不再是B的showX的subtype,我只传给了showX B的对象,但可能调用到D的showX(需要D对象,而D对象包含比B对象更多的字段,可能引发未定义错误)。这是因为this参数是特殊处理的,虽然传给showX的实参只是B对象的地址,但它同时也是D对象的地址,编译器会透明地完成这层转换,保证D的showX拿到的是正确的D对象。这也是为什么多态要在指针下才能生效的原因(值拷贝只会拷贝值的静态类型对应内容,后面多余的派生类数据以及虚函数表信息会丢失)。
结合C++对象内存布局来回顾一下:
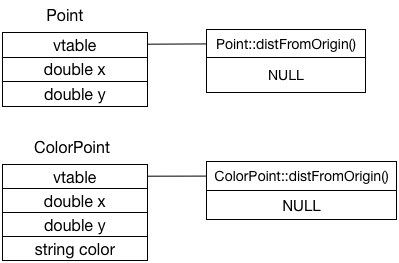
- ColorPoint对象只会基于Point对象增加字段,本身是满足subtype语义的
- ColorPoint向后追加新增字段,而不会变更基类对象的内存布局,这样可以让对象地址转换更轻量(不必做任何额外操作)
- vtable指针会在对象创建时即初始化好,不管该对象地址被转换为何种类型,vtable总是指向对象实际类型的虚函数实现(如果没实现,则指向父类该函数)
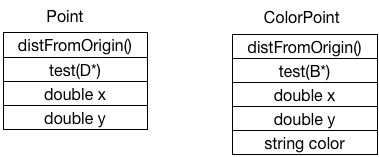
如果我们省掉vtable这些细节,将这个对象模型扩展一下,结合function depth subtype,它应该是这样:
mutiple inheritance
C++支持多重继承,为了解决多重继承的命名冲突和冗余数据的问题,它可以在subclass构造函数中指定要哪些字段用哪个superclass的。另外它提供一个叫虚继承(virtual interitance)的机制来解决菱形继承的数据冗余问题,即D继承自B,C,B,C有个共同父类A,那么C只会有一份继承自A的数据。
Java/C#不支持多重继承,它们的类只能有一个直接父类,但是可以实现多个接口(Interface),Interface是一堆方法的集合,它没有任何实现,当然也不能实例化。相比Ruby的mixins这种”实现继承”言,这种”声明继承”更安全,因为Interface没有任何的字段,即使方法声明有冲突,子类也只需要提供一份实现,并以此为准,没有歧义。
C++还提供纯虚函数的概念,即方法本身只包含声明,没有实现,在Java中的抽象方法也提供类似的机制,包含抽象方法或纯虚函数的类就和Ruby中的mixins很像,它既可包含声明,也可包含实现,并且不能实例化对象。当类中的所有方法都为抽象方法并且不包含任何字段时,这个类也就变成了Interface。
generics
前面我们所说的subtyping(子类化),也叫做 subtype polymorphism(子类型多态) ,而另一种静态语言中常见的用于放宽type checker,提高灵活性和复用性的方案叫 parametric polymorphism(参数多态) ,也叫做generics(泛型) ,generics是很多静态语言都要考虑的一个特性,不只是OOP。比如ML就有强大的类型推导,可以实现很灵活的泛型编程。
generics用在那些需要表述任何类型的地方,即不关心对象的实际类型,通常出现在容器结构和通用算法中,比如大名鼎鼎的C++ STL,它其实就是对泛型的极致运用,封装了各类常用的容器以及各种常用算法,比如如下是一个 STL 中的 reduce 实现:
1 | template<class InputIt, class T, class BinaryOperation> |
这几行代码充分展示了STL的一些基础特性:
- 通过迭代器抽象对容器元素的基本操作: 借鉴于函数式编程,上例的
InputIt提供元素类型T的容器的操作(++,!=,*等)接口,容器本身并不出现在泛型中,它可以是任意Stack, List, Pair等提供了迭代器的标准甚至自定义容器 - 函数本身亦可泛型: 已经有函数是第一类对象的雏形,上例中的BinaryOperation既可是一个函数,也可是一个函数对象(重载了
()的对象),STL提供了很多函数对象,如加减乘除 - 大量的运算符重载: 双刃剑(方便vs隐晦),主要是为了兼容C,比如迭代器
++操作本身相当于Next() - 泛型声明本身不包含对class的任何约束说明: 依赖于编译时对泛型代码的生成来检查,并且运算符重载,隐式构造函数等特性让算法在理解和使用在有一些负担。这是个人认为还不够好的地方,对应的解决方案有: bounded generic types,下一节会提到
C++/Java/C#都提供了泛型机制,但它们的实现方式有些区别,Java的实现方式是”类型擦除(Type Erasure)”,即在编译时将List<T>变为List<Object>,然后加上一些类型检查和类型提取转换,Java运行时没有关于泛型的任何信息,它只会看到Object(动态类型语言的思路),这样最大的好处在于兼容性,即老的Java运行时也可以运行泛型代码,缺点是由于运行时不知道T的具体类型,因此无法对T进行诸如instanceof,new等操作。C#/C++的泛型则被称为”模板泛型”,即有运行时的支持,对使用者来说像是为每个类型T都生成了对应的ListT类,因此克服了Java这方面的缺点,是语义完整的。C++的template则更强大,它可以实现所谓的元编程,即在模板语法中可以使用分支(偏特化),递归等特性达到图灵完全性,如你可以通过模板语法求斐波那契数列(写法和函数式语言类似),并将运算结果或错误在编译器就吐出来,因此C++被戏称”两层语言”,一层是生成C++目标代码的函数式语言(使用模板语法),另一层才是命令式语言(C++本身)。当然这并不是C++的初衷,这里不再展开。
Go目前没有对开发者提供泛型(据说Go2.0会加入泛型),它的代码复用主要靠interface+reflect(额外运行时type check开销)或code generator(额外的复杂度和开发成本)来实现,它们只能解决很少一部分对泛型的需求,因此Go在这方面被广为诟病,比如知乎上Go有什么泛型的实现方法?的高票答案,相信大部分Gopher都深有体会:

2022.1.22更新: Go1.18中已经实现了泛型
generics vs subtyping
那么有了generics后,我们还需要subtyping么?比如前面的Pair类,如果使用subtype来完成:
1 | class LamePair { |
由于在构建LamePair时,进行了向上转换(将传入的参数转换为共同的supertype Object),因此这里实际会有类型信息丢失,当外部想要再次获取LamePair中的元素时,就不得不进行一次向下转换(downcast),如(String)e,这类转换属于run-time check,即将一部分本应在静态类型检查时暴露的错误放到了运行时,这是有悖静态类型语言的初衷的。所有的对象都属于Object,将所有的方法参数返回值都声明为Object,这是动态类型语言的思路。
因此subtyping在某些场景下不能替换generics,那反过来呢,如果我们用C++的template来实现distFromOrigin2:
1 | class Point { |
可以看到,仍然是一种很蹩脚的写法,由于泛型函数本身对类型缺乏认识,通常需要一堆辅助函数(X(),Y())来帮忙完成算法的运作,前面的STL accumulate中的迭代器类型参数也是这个作用,即便如此虽然distFromOrigin2复用了,但并没解决Point/ColorPoint的其它字段和方法的复用问题。当然,就本例而言,即便这里的ColorPoint是Point的subtype,C++ template额外生成的函数以及丢失的dynamic dispatch也提示着将distFromOrigin2实现为Point方法是更好的选择。
综上,subtype和generics各自有自己的适用情形,它们作用于不同维度。subtype是基于supertype上的操作复用,强调类与类的复用关系。而generics基于任意类型T,对T之上的容器封装(如Stack,List,Pair,Swap等)和算法复用(如Sort,Find,Reduce等),强调类通用的扩展。从另一个角度来讲,subtype可以实现运行时多态(dynamic dispatch),而generics则是编译期多态(编译期生成新的类/函数)。
事实上,Java/C#同时支持subtyping和generics,因此它们支持一种将两种结合的polymorphism: bounded generic types,核心思想是通过subtype来限制generics可接受的类型,想要鱼和熊掌兼得。比如:
1 | class Bound<T extends Point> |
这样,通过subtype让Bound对传入的T有一定的基本认知,可以调用Point的方法(无需外部传入),通过generics让这些基于Point类之上的算法可复用。
oop in golang
我将Go单独放到一节,因为它与我们熟知的C++/Java/C#/Ruby等OOP语言很不一样,它有一些创新的地方,用来解决那些困扰了OOP几十年的难题。
如果按照我们前面给出来的OOP定义,Go是OOP语言,或者说它可以实现OOP编程范式。但是Go没有继承(is-a)的概念,即没有subclass的概念,如果一门OOP语言没有subclass,那么我们会考虑两个问题: 1. Go如何实现class代码复用?2. Go如何实现subtype? 下面分别讨论这两个问题。
Go没有is-a的概念,它推崇composition over inheritance principle原则,即组合胜于继承,用has-a替代is-a:
1 | type A struct { |
以上代码展示了Go如何通过组合而非继承来实现代码复用,当B需要复用A的代码时,它将A声明为类的一个匿名字段,之后就可以通过B来访问A中的方法和字段,当然这里也需要一套名字查找规则: 1. 先查找B中有没有对应的方法和字段 2. 再从后往前查找B中的匿名字段有无该方法和字段。因此可以通过B调用A的方法实际上是编译器的语法糖,并不是dynamic dispatch,因为Go只能通过子类对象调用子类方法,而不能通过父类对象调用子类方法。事实上,Go的子类对象无法转换为父类对象,从实现上来说,它们就是组合关系,你可以动态将B中的A字段赋为其它A对象。当然,这里的”父类””子类”叫法是不严谨的,因为Go没有subclass。
解决了面向对象的代码复用问题,我们再来看Go如何实现subtype,Go的subtype不是通过subclass来实现的,而是通过Interface来实现的:
1 | type Printer interface { |
在Java/C#/Go中,都有Interface的概念,但Java/C#的接口实现是需要显式声明的(即类在定义时就知道自己实现了哪些接口),但是Go的接口不需要显式声明implement,可以在运行时动态判断(实现细节参考这里),这个特性为程序提供了极大的灵活性。A,B并不知道自己实现了Printer接口,它在定义的时候甚至还没有出现Printer接口,或者只有个类似Ouputter之类的接口包含相同的方法,Interface将类如何定义和类如何被使用分离开,比如你只要实现了Read(p []byte) (n int, err error)方法,就实现了io.Reader接口,就可以使用ioutil.Read/ReadAll等lib API。
总结一下,Go通过组合加编译器的一些静态查找规则来实现代码复用,通过Interface来实现subtype,而如C++/Java/C#等语言用subclass来同时提供两种功能,因此导致类关系错综复杂,甚至一度被戏称COP(Class-oriented programing)而非OOP。虽然Interface实现的subtype不如subclass实现的subtype一样强大(Interface只是方法声明集合,而superclass还包含字段),但Interface的灵活性远胜于需要显式指定的superclass,并且避免了OOP继承长久以来的痛点。
dynamic type vs static type
简单来说,静态语言的设计宗旨是尽可能在静态检查中多做事情,通过静态检查来过滤大部分的类型错误,优点是程序运行更稳定,Debug也更容易,缺点是会一定程度限制代码设计的灵活性,因此通常需要subtype来在通过规则放宽type check的限制。
而动态语言的设计宗旨是优先支持更灵活的代码设计(如duck typing),将type check放到了run-time,优点是程序更灵活,开发效率通常更高,但程序运行的稳定性会差一些,遇到问题的调试也要更复杂。毕竟没有静态类型检查,允许了更灵活的设计,也放行了很多类型错误。
oop vs fp
计算机业界有句古老的名言: “程序=数据结构+算法”。
OOP(Object-oriented programming)偏向数据结构,函数只是数据结构的行为(对象的方法),通过class来封装对象,通过subclass来复用对象。OOP的终极奥义是: 一切皆对象,甚至对象的类也是对象。
FP(Functional programming)偏向算法(函数),即函数为第一类值,数据只是函数的参数或者执行环境(闭包)。用闭包,柯里化,高阶函数等去完成函数的封装和复用。FP的终极奥义是: 一切皆函数,连数据也可以是函数。
举个例子,我们可以将数据结构和算法分为两个维度,做成一个表格:
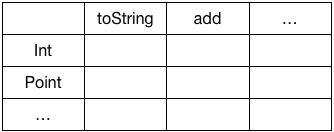
表的行表示各种数据类型,列为对应的操作。每个编程语言必须要做的就是定义每种数据类型执行每种操作时的行为。
OOP的做法是按照各个行划分,定义各个数据结构的类,然后在类上面实现该类型所支持的各个方法。而FP的做法是按照各个列划分,定义各个函数,如toString,然后在函数中去区分各个数据类型并实现。
从这个角度来说,FP和OOP只是以不同的方式来组织你的代码,OOP按照数据来聚合,FP按照函数来聚合,如果使用OOP,那么添加数据类型很方便,你只需要在新定义的类中去实现它支持的操作,无需影响其它已有类。同理如果使用FP,则新添加一个函数很方便。
另一个比较有意思的点是,FP的二元操作要比OOP更直观,比如我们的add操作:
1 | fun add (v1,v2) = |
在FP中,二元操作很直观,add(Point, Int)和add(Int, Point)可以复用,而在OOP中:
1 | class Int |
上面的代码虽然也算直观,但有两个问题,一是代码复用不好,Int.addPoint和Point.addInt的实现其实是一样的,即使想要复用代码,只用一份实现,那这份实现应该放在Int类还是Point类呢?第二个问题是这里其实是将FP和OOP混着用,在OOP中,应该尽量避免通过运行时判断对象属于哪个类,纯正的OOP应该通过函数调用+dynamic dispatch来避免类型判断:
1 | class Int |
现在虽然是纯正的OOP了,但实际上维护这些代码却很麻烦,假设我们增加一个String类型,它也可以参与add运算,那么除了定义String类型本身以外,我们还需要去已有所有类型中添加addString方法,在这种情况下,OOP增加一个数据类型也不那么方便了。
- 静态OOP语言如C++/Java/C#可能会提供一种重载的机制,允许同一个方法名不同的类型参数,编译器会自动选择匹配的函数调用。这能够避免运行时的类型检查,也不用二次分发,但复用性和扩展性仍然不好。
- 在Java/C#中,可以通过Interface来声明所有的addInt/Point方法,让Int,Point实现这个接口,这样在添加String类型时,在Interface中添加addString方法,静态类型检查能够保证所有的子类都实现了addString
PS: 这里只是从程序结构的角度对比FP和OOP,事实上FP的一些理念还来自于lamda演算和数学领域,因此大部分的FP语言还有不可变语义,纯函数等特性。
FP或OOP或其它的编程范式,本质上是以不同的方式对现实问题进行建模,不管是”一切皆函数”还是”一切皆对象”,都是理想化的解决方案。现实中可能没有编程语言完美实现了某一编程范式,更多地是借鉴和吸收,同时支持多种编程范式,毕竟语言是用来解决问题的。