Go基于CSP模型,提倡”Share memory by communicating; don’t communicate by sharing memory.”,亦即通过channel来实现goroutine之间的数据共享,但很多时候用锁仍然是不可避免的,它可以让流程更直观明了,并且减少内存占用等。通常我们的实践是用channel传递数据的所有权,分配工作和同步异步结果等,而用锁来共享状态和配置等信息。
本文从偏实现的角度学习下Go的atomic.Load/Store,atomic.Value,以及sync.Map。
1. atomic.Load/Store
在Go中,对于一个字以内的简单类型(如整数,指针),可以直接通过atomic.Load/Store/Add/Swap/CompareAndSwap系列API来进行原子读写,以Int32为例:
1 |
|
一个有意思的问题,在64位平台下,对Int32,Int64的直接读写是原子的吗?以下是一些有意思的讨论:
- http://preshing.com/20130618/atomic-vs-non-atomic-operations/
- https://stackoverflow.com/questions/46556857/is-golang-atomic-loaduint32-necessary
- https://stackoverflow.com/questions/5258627/atomic-64-bit-writes-with-gcc
总结就是,现代硬件架构基本都保证了内存对齐的word-sized load和store是原子的,这隐含两个条件: 单条MOV, MOVQ等指令是原子的,字段内存对齐(CPU对内存的读取是基于word-size的)。但安全起见,最好还是使用atomic提供的接口,具备更好的跨平台性,并且atomic还提供了一些复合操作(Add/Swap/CAS)。golang也在实现上会对具体平台进行优化:
1 | var i int64 |
在MacOS10.12(X86_64)下,对应汇编代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// var i int64
tmp.go:9 0x1093bff 488d051af50000 LEAQ 0xf51a(IP), AX // 加载int64 type
tmp.go:9 0x1093c06 48890424 MOVQ AX, 0(SP)
tmp.go:9 0x1093c0a e8c1a1f7ff CALL runtime.newobject(SB) // i分配在堆上(逃逸分析,escape analytic))
tmp.go:9 0x1093c0f 488b442408 MOVQ 0x8(SP), AX
tmp.go:9 0x1093c14 4889442450 MOVQ AX, 0x50(SP) // 0x50(SP) = &i
tmp.go:9 0x1093c19 48c70000000000 MOVQ $0x0, 0(AX) // 初始化 i = 0
// atomic.StoreInt64(&i, 123)
tmp.go:10 0x1093c20 488b442450 MOVQ 0x50(SP), AX // 加载&i
tmp.go:10 0x1093c25 48c7c17b000000 MOVQ $0x7b, CX // 加载立即数 123
tmp.go:10 0x1093c2c 488708 XCHGQ CX, 0(AX) // *(&i) = 123 Key Step XCHGQ通过LOCK信号锁住内存总线来确保原子性
// x := atomic.LoadInt64(&i)
tmp.go:11 0x1093c2f 488b442450 MOVQ 0x50(SP), AX
tmp.go:11 0x1093c34 488b00 MOVQ 0(AX), AX // AX = *(&i) Key Step 原子操作
tmp.go:11 0x1093c37 4889442430 MOVQ AX, 0x30(SP)
// y := atomic.AddInt64(&i, 1)
tmp.go:12 0x1093c3c 488b442450 MOVQ 0x50(SP), AX
tmp.go:12 0x1093c41 48c7c101000000 MOVQ $0x1, CX
tmp.go:12 0x1093c48 f0480fc108 LOCK XADDQ CX, 0(AX) // LOCK会锁住内存总线,直到XADDQ指令完成,完成后CX为i的旧值 0(AX)=*(&i)=i+1
tmp.go:12 0x1093c4d 488d4101 LEAQ 0x1(CX), AX // AX = CX+1 再执行一次加法 用于返回值
tmp.go:12 0x1093c51 4889442428 MOVQ AX, 0x28(SP)
对XCHG和XADD这类X开头的指令,都会通过LOCK信号锁住内存总线,因此加不加LOCK前缀都是一样的。可以看到,由于硬件架构的支持,atomic.Load/Store和普通读写基本没有什么区别,这种CPU指令级别的锁非常快。因此通常我们将这类CPU指令级别的支持的Lock操作称为原子操作或无锁操作。
2. atomic.Value
atomic.Value于go1.4引入,用于无锁存取任意值(interface{}),它的数据结构很简单:
1 | // sync/atomic/value.go |
atomic负责v的原子存取操作,我们知道interface{}对应的数据结构为eface,有两个字段: type和data,因此它不能直接通过atomic.Load/Store来存取,atomic.Value实现无锁存取的原理很简单: type字段不变,只允许更改data字段,这样就能通过atomic.LoadPointer来实现对data的存取。从实现来讲,atomic.Value要处理好两点:
- atomic.Value的初始化,因为在初始化时,需要同时初始化type和data字段,atomic.Value通过CAS自旋锁来实现初始化的原子性。
- atomic.Value的拷贝,一是拷贝过程的原子性,二是拷贝方式,浅拷贝会带来更多的并发问题,深拷贝得到两个独立的atomic.Value是没有意义的,因此atomic.Value在初始化完成之后是不能拷贝的。
除此之外,atomic.Value的实现比较简单,结合eface和atomic.LoadPointer()即可理解,不再详述。
3. sync.Map
sync.Map于go1.9引入,为并发map提供一个高效的解决方案。在此之前,通常是通过sync.RWMutex来实现线程安全的Map,后面会有mutexMap和sync.Map的性能对比。先来看看sync.Map的特性:
- 以空间换效率,通过read和dirty两个map来提高读取效率
- 优先从read map中读取(无锁),否则再从dirty map中读取(加锁)
- 动态调整,当misses次数过多时,将dirty map提升为read map
- 延迟删除,删除只是为value打一个标记,在dirty map提升时才执行真正的删除
sync.Map的使用很简单:
1 | var m sync.Map |
下面看一下sync.Map的定义以及Load, Store, Delete三个方法的实现。
3.1 定义
1 | // sync/map.go |
定义很简单,补充以下几点:
- read和dirty通过entry包装value,这样使得value的变化和map的变化隔离,前者可以用atomic无锁完成
- Map的read字段结构体定义为readOnly,这只是针对map[interface{}]*entry而言的,entry内的内容以及amended字段都是可以变的
- 大部分情况下,对已有key的删除(entry.p置为nil)和更新可以直接通过修改entry.p来完成
3.2 Load
1 | // 查找对应的Key值 如果不存在 返回nil,false |
3.3 Store
1 | // Store sets the value for a key. |
3.4 Delete
1 | // Delete deletes the value for a key. |
3.5 总结
除了Load/Store/Delete之外,sync.Map还提供了LoadOrStore/Range操作,但没有提供Len()方法,这是因为要统计有效的键值对只能先提升dirty map(dirty map中可能有read map中没有的键值对),再遍历m.read(由于延迟删除,不是所有的键值对都有效),这其实就是Range做的事情,因此在不添加新数据结构支持的情况下,sync.Map的长度获取和Range操作是同一复杂度的。这部分只能看官方后续支持。
sync.Map实现上并不是特别复杂,但仍有很多值得借鉴的地方:
- 通过entry隔离map变更和value变更,并且read map和dirty map指向同一个entry, 这样更新read map已有值无需加锁
- double checking
- 延迟删除key,通过标记避免修改read map,同时极大提升了删除key的效率(删除read map中存在的key是无锁操作)
- 延迟创建dirty map,并且通过p的nil和expunged,amended字段来加强对dirty map状态的把控,减少对dirty map不必要的使用
sync.Map适用于key值相对固定,读多写少(更新m.read已有key仍然是无锁的)的情况,下面是一份使用RWLock的内建map和sync.Map的并发读写性能对比,代码在这里,代码对随机生成的整数key/value值进行并发的Load/Store/Delete操作,benchmark结果如下:
1 | go test -bench=. |
可以看到,除了并发写稍慢之外(并发写随机1亿以内的整数key/value,因此新建key操作远大于更新key,会导致sync.Map频繁的dirty map提升操作),Load和Delete操作均快于mutexMap,特别是删除,得益于延迟删除,sync.Map的Delete几乎和Load一样快。
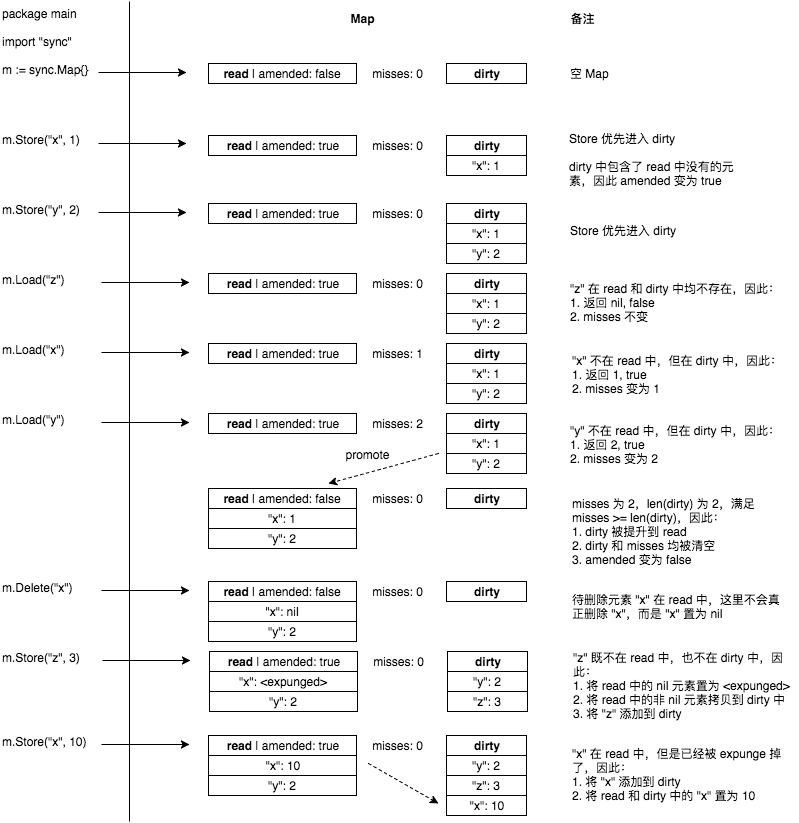
最后附上一份转载的sync.Map操作图解(图片出处):