学习一下go中常用的几种数据结构,结合源码了解其实现原理。
一. 类型系统
1. array
1 | func f(x [2]int){ |
array的特性:
- 固定大小,且大小为类型的一部分
- 数组元素在内存中连续存放
- 值语义: 数组本身(传参会完整拷贝数组)
2. slice
数组切片
slice(切片),提供描述array部分连续元素的能力。
A slice is a data structure describing a contiguous section of an array stored separately from the slice variable itself. A slice is not an array. A slice describes a piece of an array.
slice只持有array的引用,而不会拷贝元素,因此它在实现上只需持有指向array元素的pointer和slice长度length即可。但由于slice的length可以收缩或扩张,因此slice还需要一个字段capacity来保存其最初引用的array的size,当length > capacity时,说明对array的访问越界,触发panic错误。
因此slice一共有三个字段:
1 | type sliceHeader{ |
比如:
1 | // 直接创建slice 等价于: |
此时a,b的sliceHeader示意图为:
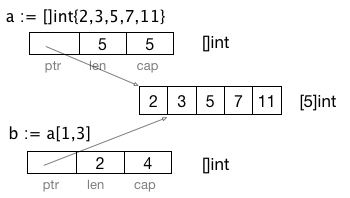
由于slice b在slice a中的起始偏移为1,因此 cap(b) = cap(a)-1 = 4。但b只能访问到a[1],a[2]两个元素:
1 | // 尝试访问>=length(2)的元素,会触发panic error |
那么slice这种数组切片的概念,究竟带来了什么好处?比如我们有一个操作,要去掉数组的首尾元素,在C中,我们会创建(动态分配)一个新数组,然后将arr[1,n-1)拷贝出来。在C++中,有vector会方便一些,但移除元素会导致后续元素移动拷贝开销。而在Go中,slice = slice[1:len(slice)-1]即可完成操作,这中间不会涉及到内存分配,移动拷贝等,是个非常高效的操作。当然,由于slice是引用的数组元素,因此slice修改数组元素时,对其它引用到该元素的slice也是可见的。
下面来说说slice的值语义。前面提到的sliceHeader,实际就是slice的值语义,我们创建一个slice,在底层就创建了一个sliceHeader结构体。在参数传递时,将会拷贝sliceHeader,但由于sliceHeader中持有指针,因此在调用函数内可修改数组元素,但无法修改sliceHeader结构体的成员值:
1 | func Extend(slice []int, element int ){ |
再次摘录一段golang blog关于slice值语义的描述:
It’s important to understand that even though a slice contains a pointer, it is itself a value. Under the covers, it is a struct value holding a pointer and a length. It is not a pointer to a struct.
BTW,在Go里面的参数传递都是值传递的,只是针对各种类型,其值语义不同,比如int,array它们的值语义就是数据本身,不包含对外的引用(指针),因此在传参时会完整拷贝整个数据,当然,这里的拷贝是浅拷贝,比如对指针数组这类结构而言,仍然是有副作用的,但这是应用层的东西,就数组容器本身而言,是值拷贝的。而对slice来说,其值语义中包含对数组的引用,因此在传参时,其引用内容可能被修改,但其值语义(sliceHeader)本身仍然是完整拷贝的。
动态数组
前面提到slice本质上是数组切片,但slice本身也可以作为动态数组:
1 | func main(){ |
append会在len(s)+添加的元素个数>cap(s)时,重新分配(make)一个slice,拷贝(copy)已有元素,添加新元素,最后返回这个新的slice。在使用append时,需要保存其返回值,因为append传入的是slice的值,也就是sliceHeader结构体,当slice capacity扩展时,append函数内不能修改sliceHeader中的Length和Capacity字段,因此需要返回一个新的sliceHeader。
为了避免混淆,不要像上例一样将slice的切片特性和动态数组特性混用,使用动态数组时,使用空的slice(var s []int)或make(make([]int, len, cap))初始化一个slice会比较好。
3. string
Go中的string更像是C中的字符串字面量,而不是字符数组:
1 | str := "Hello, 世界" |
在实现上,string是个read-only byte slice,另外,string的”sliceHeader”没有capacity字段:
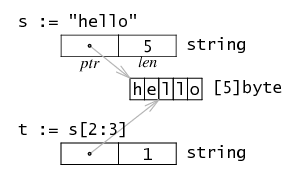
s := "hello"
t := s[2:3] // "l"
v := t[0:2] // 没有capacity字段,无法扩展,触发panic error: out of range
由于string的slice特性,len(s)操作非常高效,字符串切割也给代码处理带来很高的灵活度,如官方runtime/string.go的atoi函数是这样写的:
func atoi(s string) int{
n := 0
for len(s) > 0 && '0' <= s[0] && s[0] <= '9' {
n = n*10 + int(s[0]) - '0'
s = s[1:]
}
return n
}
PS,slice的这种切片特性,与Erlang的refc binary和sub binary实现有相似之处,这种高效的处理方案有个老大难问题,那就是slice string未释放,那么它引用的string本身也不会被GC,哪怕只引用了很小一部分。
4. map
map通过hash表实现,实现位于runtime/hashmap.go,以下是主要字段:
1 | const( |
摘自源码注释:
A map is just a hash table. The data is arranged into an array of buckets. Each bucket contains up to 8 key/value pairs. The low-order bits of the hash are used to select a bucket. Each bucket contains a few high-order bits of each hash to distinguish the entries within a single bucket.
If more than 8 keys hash to a bucket, we chain on extra buckets.
When the hashtable grows, we allocate a new array of buckets twice as big. Buckets are incrementally copied from the old bucket array to the new bucket array.
hmap的buckets数组大小为2^B,通过取余(hash(key)&(1<<B-1))可得到key对应的bucket在buckets数组中的下标,每个bucket可以容纳2^bucketCntBits=8个key/value对,落到该桶的key个数超过8个时,会在堆上分配一个新的bucket,并挂在链表末,因此go hashmap通过链表(8个元素一组)来解决hash碰撞问题。
go的hash map使用的是可扩展hash算法,在负载因子loadFactor(hmap.count/(1<<B))大于某个值(这个值太大会导致overflow buckets过多,查找效率降低,过小会浪费存储空间,经源码作者测试确认为6.5)时,进行hash扩展。此时B=B<<1,原有buckets由oldbuckets指向,新的buckets重新分配,此时由于hash表大小变更,部分key得到的buckets下标也会改变,因此需要将oldbuckets中的数据按照新的hash表大小重新迁移(evacuate),出于效率考虑,这个操作是增量进行的,在hash map每次写入时,都会尝试迁移两个bucket(以及后续overflow bucket),一个是写入的目标bucket(局部迁移),一个是hmap.evacuate指向的bucket(增量迁移),这样兼顾局部性和全局性,同时也能保证在新的buckets loadFacotr到达6.5前,所有迁移工作一定能完成。迁移工作完成后,oldbucket置为nil。PS: hash map通过bucket的tophash[0]来标记bucket的迁移状态,保留的标记值为0-3,key的tophash在这个范围内时,会被+4修正
上述是基于go1.5 hashmap实现,在go1.8中,添加了sameSizeGrow,当overflow buckets的数量超过一定数量(2^B)而负载未大于阀值6.5时,此时可能存在部分空的bucket,即bucket未有效利用,这时会触发sameSizeGrow,即B不变,但走数据迁移流程,将oldbuckets的数据重新紧凑排列提高bucket的利用率。当然在sameSizeGrow过程中,不能触发loadFactorGrow。
下面来看个结构图:
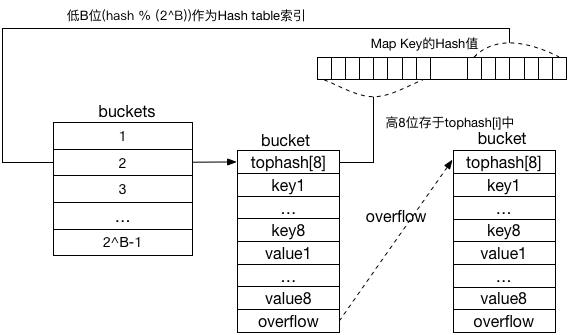
再来看Key查找过程(简化版):
1 | // From go 1.8.1 src/runtime/hashmap.go |
限于理解深度,其它一些细节没有提到,比如对不含pointer的key/value优化,另外,go map还针对常用key类型(如int32,int64,string)进行了特例优化,代码位于src/runtime/hashmap_fast.go。以下是上面已经提到的一些小的优化细节:
- key value采用k1,k2,..v1,v2,…排列,而不是k1,v1,k2,v2,这是出于内存对齐考虑,节约空间
- tophash可用于加快key的查找,同时用于标记key的迁移状态
- map大小是2的幂,因此hash值可快速求余: hash(key)&(1<<B-1)
- hash map的增量式扩展,sameSizeGrow
其它:
- go map不支持并发
- go map目前只有扩展 没有收缩操作(shrink)
- go map迁移时,会创建新的bucket,而不会复用oldbucket中的overflow bucket(作者TODO里面)
值语义:如hmap结构体所示,buckets为bucket指针数组,那么对key,value的操作都是引用语义的。
5. channel
channel是goroutine用于数据交互的通道,和Erlang的Actor以通信实体为第一类对象不同(Actor模型),Go以通信介质作为第一类对象(CSP模型),channel支持多写入者和读取者,并且可通过缓冲来实现同步/异步(一定数量)通信。
在实现上,channel其实就是个消息队列:
1 | // 省略部分字段 |
下图描述了一个缓冲区大小为5,并阻塞了若干读goroutine的情况:
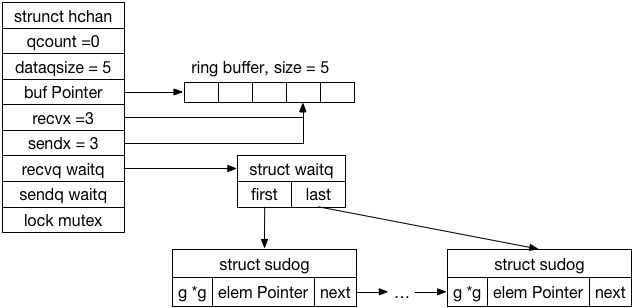
该图省略了hchan和sudog的部分字段,waitq在实现上是双向链表,虽然实际只会用到单链表语义(FIFO)。
根据上图情形,此时如果有其它goroutine写入channel:
- 从recvq中pop第一个读写者的sudog
- 将写入channel的数据拷贝到该sudog的elem字段
- 唤醒该读写者goroutine(sudog.g)
当recvq队列为空,此时写入:
- 将写入的数据缓存到buff[sendx]
- sendx环形自增,qcount++
当buff缓冲区写满(qcount==dataqsiz),此时写入:
- 为写入者创建一个sudog,并插入到sendq队列末
- 挂起该写入者goroutine
如果此时有goroutine再次读channel:
- 从buf[recvx]读取第一个数据
- 从sendq中pop第一个阻塞的写入者goroutine(sudog)
- 将该sudog中的elem字段数据拷贝到buf[recvx],相当于将elem数据push到buf末尾
- recvx++
- 唤醒该发送者goroutine
没有缓冲的channel(dataqsize==0)操作要简单一些,写入时如果recvq->first!=nil,则直接拷贝数据到读取者的elem字段,否则将写入者挂起。反之,读写过程也类似。
另外,由于一个goroutine读写多个channel,因此go提供语言级别的select,用于处理异步IO问题。这其实本质上仍然是尝试对channel进行读写操作(chanrecv),只不过由block参数为false表明该读写不阻塞,当读写操作需要挂起时,立即返回false。而select操作本身其实就是个多分支的if-elseif-else表达式:
1 | src/runtime/chan.go |
select的if-elseif-else语句分支顺序是随机的,在每次执行select时会将所有scase(包含hchan)顺序随机排列。参考src/runtime/select.go hselect和scase结构体。
通过cap(chan)和len(chan)可以获取channel的缓冲区大小(dataqsize)和当前消息数量(qcount)。
6. interface
interface接口的用法和实现放到go面向对象和go interface实现中。
7. make & new
go中有make和new两个关键字用于分配一个对象,简要提一下两者的区别:
内建函数 new 用来分配内存,它的第一个参数是一个类型,不是一个值,它的返回值是一个指向新分配类型零值的指针
内建函数 make 用来为 slice,map 或 chan 类型分配内存和初始化一个对象(目前只能用于这三种类型),跟 new 类似,第一个参数也是一个类型而不是一个值,跟 new 不同的是,make 返回类型的引用而不是指针,而返回值也依赖于具体传入的类型,具体使用如下:
// 等价于 a := [capacity]int{} s := a[0:2]
s := make([]int, length [,capacity])
m := make(map[int]string [,size])
c := make(chan int, [,length])
8. 常量
Go中的常量是无类型的,字面常量(如:3.14, “ok”)是无类型的,可以赋给任何满在其值域中的类型。Go预定义了三个常量:true, false, iota,其中iota是一个可以被编译器修改的常量,它代表一个整数,在每个const出现时被重置为0,然后iota每出现一次,其所代表的值即自增一次。iota通常用来定义枚举值,这类值应用程序不关心具体数值,只需确保其在同一个const枚举声明中不会冲突即可。
const (
c0 = iota // c0 == 0
c1 = iota // c1 == 1
c2 = iota // c2 == 2
)
// 根据枚举定义相同表达式的缩写,等价于
const (
c0 = iota // c0 == 0
c1 // c1 == 1
c2 // c2 == 2
)