Hash算法
Hash算法本质是将一个值域(也称定义域,通常更大)映射到另一个值域(通常更小),比如SHA-2,MD5等。Hash算法有一些共有特性,比如确定性,不可逆性。Hash算法被广泛应用于加密,Hash表,文件校验等领域。
分布式系统中常用Hash算法来进行任务分配,比如我们要设计一个分布式存储系统,通过Hash算法能够有序均匀地将N个任务分配到M个节点(Hash槽)上:
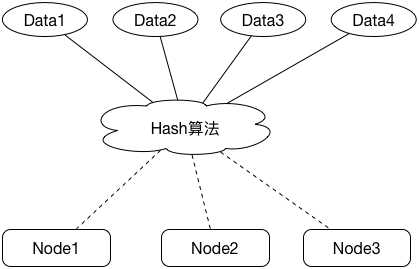
这里的Hash算法的主要作用是将任务均摊到各个Hash槽中,比如我们有1000W份data和100个node,我们可以简单通过取MD5值再取余的方式来分配任务,代码实现normal_hash.py
1 | # -*- coding: utf-8 -*- |
在我们的分布式存储系统中,我们从两个方面来评估一个Hash算法:
- Hash算法分配是否均匀,即数据是否均匀地分布在各个节点上
- 当一个节点挂掉时,需要迁移(即前后Hash不一致)的数据量大小
我写了个简单的测试用例来评估以上两项,代码实现test.py:
1 | NODES1 = 100 |
针对我们的NormalHash,输出如下:
Ave: 100000
Max: 100695 (0.69%)
Min: 99073 (0.93%)
--- Node[99] Down, Datas: 100212
Ave: 101010
Max: 101731 (0.71%)
Min: 100129 (0.87%)
Change: 9900142 (99.00%)
可以看到,基于MD5再取模的Hash算法能够很好地将1000W个任务均摊到各个节点上,但传统Hash存在一个问题,就是当Hash槽变动时,需要对所有关键字重新映射,并导致大量的任务迁移。我们的NormalHash迁移的数据条目数占总条目数的99%,而实际上需要迁移的数据量只有1%左右,也就是说,为了提升1%的可用性,我们需要迁移99%的数据,这无疑是很难接受的。而我们想要这样一种Hash算法,在节点变动时,已映射的条目尽可能不变,只需要迁移变更节点(故障节点或新增节点)上的数据,这就是一致性Hash算法的提出背景。
一致性Hash
以下是Wiki给出的一致Hash的定义:
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的VNode表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
1. Ring Hash
针对我们上个问题提出的需求,我们可以考虑一种实现:当节点挂掉时,将故障节点上的数据转移到另一个节点上去,其它已有节点和数据的映射不变,这样迁移的数据更少。为了快速找到某个节点的替代节点,可以将所有节点想象成一个环(ring),每次我们找到这个节点在环上的后继节点:
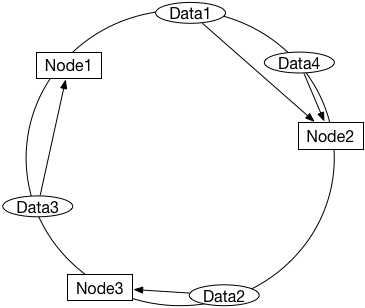
如图,当Node3挂掉时,其上的Data2将迁移到Node2。我们可以设计一个RingHash类,代码实现ring_hash.py:
1 | class RingHash: |
复用我们上面写的测试用例,看一下测试结果:
Ave: 100000
Max: 596413 (496.41%)
Min: 103 (99.90%)
--- Node[99] Down, Datas: 65656
Ave: 101010
Max: 596413 (490.45%)
Min: 103 (99.90%)
Change: 65656 (0.66%)
如我们所料,现在迁移率更低了,只会迁移挂掉的节点上的那部分数据,将其移到其环上的下一个节点上。这种方案和NormalHash的本质不同在于RingHash基于范围,在NormalHash中,Hash槽变动会导致Hash环变小([0~99]->[0~98]),最终变更了数据落在环上位置,而在RingHash中,数据和节点落在Hash环上的位置是不变的(Hash环本身没变),变更的是位置到节点的映射。
现在来看看RingHash的分配效果,出乎意料地差,节点间的数据量差距最大达6000倍。这是因为虽然1000W数据的Hash值分布仍然是相对均匀的,但100个节点的Hash值分布却不是(定义域太小),这种环形算法在数据分配上面是不能满足需求的。这个算法还有一个问题,就是将故障节点上所有的数据都重新分配到了同一个节点,容易造成热点放大。
2. Ring Hash + Virtual Node
为了让节点的Hash在环上相对分布均匀,我们可以让一个节点对应多个Hash值,即中间加一层虚拟节点(Virtual Node,以下简称VNode),然后再由虚拟节点映射到真实节点(Node)。
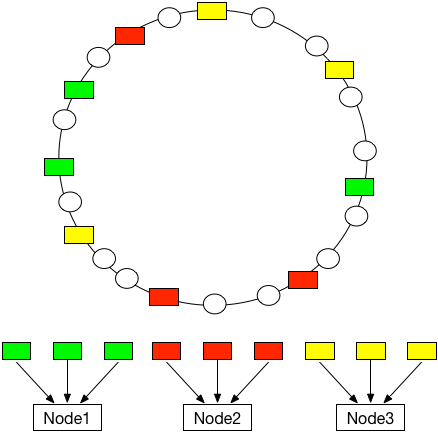
比如我们让每个Node对应100个VNode,一共10000个VNode的Hash值分布在环上,代码实现ring_hash_vnode.py:
1 | class RingHashVNode: |
统计分配情况:
Ave: 100000
Max: 124605 (24.61%)
Min: 81856 (18.14%)
--- Node[99] Down, Datas: 116555
Ave: 101010
Max: 125236 (23.98%)
Min: 83320 (17.51%)
Change: 116555 (1.17%)
现在数据分配效果理想了很多,数据迁移量也达到最小,并且由于虚节点的存在,被迁移的数据项(分布在环的各个位置)会向就近的VNode迁移,最终相对均匀地落在各个Node上。
3. Ring Hash + Fixed HashVirtual Node
虚拟节点方案本质上通过VNode将节点Hash尽可能更均匀地分布在Hash环上,那么实际上我们可以将Hash环固定地分为N份(N个VNode),再通过维护VNode到Node的映射来完成任务分配,这样在节点变更时,Hash环也是稳定的,代码实现ring_hash_fixed_vnode.py:
1 | class RingHashFixedVNode: |
注意到当节点变更之后,我们需要根据当前的VNode->Node的映射进行变更,因此两次Hash不是独立的,在测试时,我们需要这样生成两次对比的Hash算法:
1 | hash1 = RingHashFixedVNode(NODES1) |
测试结果为:
Ave: 100000
Max: 100695 (0.69%)
Min: 99073 (0.93%)
--- Node 99 Down, Datas: 100212
Ave: 101010
Max: 102381 (1.36%)
Min: 100087 (0.91%)
Change: 100212 (1.00%)
这个算法不仅数据分配更均匀(1000个固定VNode,比RingHashVNode的10000个VNode分配情况要好得多),数据迁移量也最少,并且计算上也会更快,因为不需要计算VNode的Hash,也不需要基于范围进行bisect_left插入排序操作,在VNode层级,它和普通Hash一样简单快捷,在节点变更时,变更的只是VNode->Node的映射,并且通过手动维护这份映射(而不是再次通过自动取余等操作),将数据迁移降到最低。
RingHashFixedVNode还有一定的优化空间,比如通过将VNode个数设为2的幂,以通过位运算(<<)来取代取余(%)操作等。这里不再赘述。